![]() 269
269
UN PROCEDIMIENTO PARA LA CONSTRUCCIÓN DE LAS BASES DE CONOCIMIENTO DE UN
SISTEMA EXPERTO DE TIPC! ...SENTIDO COMÚN"
Esther Vargas
Escuela de Ciencias dela Educación, Un versidad La saue
RESUMEN
Existen dos clases generales de sistemas expertos: los tradicionales, en los cuales los conocimientos y sus reglas son dados por expertos, y los de tipo "sentido común", los cuales son más recientes. En este segundo tipo de sistema experto, es difícil la creación de la base de conocimientos debido a que se obtiene de diferentes personas y que es de tipo incierto e impreciso. En este trabajo se presenta una metodologfa que consiste en: a) cap1ar, de grandes grupos de individuos, definiciones de conceptos referentes a un tema, b) organizar los datos obtenidos por métodos estadísticos sencillos y e) construir las es semánticas clásicas del grupo o grupos; se muestra como con esta infonnación es posible confonnar la base de datos para un sistema experto de tipo "sentido común".
ABSTRACT
There are two general klnds of expert systems: the tradltional ones, which rely on knowledge and rules given by expert -usually few of them-, and other type of systems which are recently developed: expert systems based in "common sense" understanding. The creation of the basics of knowledge is difficult, because this is obtained by different persons and it is the kind uncertain and imprecise. The current study shows a methodology consisting in: a) ask to large group of individuals for definitions of concepts relatíng to a topic, b) organize data by simple statistical methods, and c) build classic semantic nets from data; with this infonnation, ucommon sense· expert system databases can be developed.
INTRODUCCIÓN
En pocos ai'\os, los Sistemas Expertos (SE) han pasado de los laboratorios de Investigación a aplicaciones específicas. en el campo industrial, médico, etc. La novedad introducida por los SE en relación con la computación clásica es esencialmente metodológlca. Consiste en separar lo más posible el conocimiento de un dominio de la fonna de utilizar ese conocimiento; lo que corresponde a considerar todo el conocimiento de un dominio como datos para un programa computacional, que no es entonces mas que una simulación de un razonamiento sobre este conocimiento. Esta idea es simple, pero corresponde a un cambio radical en la metodologla de la programación. Se trata ahora de hacer explfcito, de representar, de actualizar, de enriquecer Jos conocimientos de un dominio, es decir, de REALIZAR UN MODELO FORMAL.
Antes de pasar a la metodología objeto de este trabajo, en primer término se presenta una breve explicación de cómo surgen y qué son los SE. Un sistema experto se puede definir como un sistema computacional en el que la base de conocimiento (conjunto de información proporcionada por un agente experto) es independiente del motor de inferencia (núcleo del sistema que pone en marcha los elementos de la base de conocimiento sobre aplicaciones específicas) que construye el razonamiento. Es por Jo que se les denomina "Sistemas basados en conocimiento" (Knowledge Base Systems).
Estos programas tienen la particularidad de poseer el "saber hacer" de los especialistas humanos y la de obtener productos de buena calidad. Los SE adquieren el conocimiento especializado a través de un experto en el dominio, almacenando aquél en su base de conocimientos. La elección del fonnalismo utilizado para modelar ese conocimiento es
![]() 269
269

crucial para una manipulación eficaz de los datos.
Existen diferentes fonnalismos, dentro de los que se encuentran: lógica de primer orden, reglas de producción, objetos, esquemas.redes semánticas, etc. El más utilizado es el de reglas de producción, el cual se puede entender con el siguiente ejemplo:
"Si el coche no arranca y los faros no alumbran, entonces, existe una evidencia sugerente (0-9) de que la batería está fuera de servicio•. Esta regla se emplea para deducir el hecho de que la baterfa está fuera de servicio, si anterionnente el sistema ha comprobado
que el coche no arranca y que los faros no alumbran.
El tratamiento del conocimiento se realiza mediante un motor de Inferencias, cuyo mecanismo de razonamiento se puede guiar, ya bien por los objetivos, ya bien por los datos.
Los sistemas expertos se destacan por su fonnalismo de representación del conocimiento y por su mecanismo de
razonamiento. Una de las primeras investigaciones en SE fue la realizada por Feigenbaum, Buchanan y Lederberg, desde 1965, con el programa DENDRAL. Se interesaron en la representación de los mecanismos de razonamiento inductivo y emplrico concernientes al problema de
ªconstruir la mejor hipótesis que dé una buena interpretación de un conjunto de datos•; el área de experimentación elegida fue el análísis qulmico de los datos del espectrómetro de masas.
Enseguida, este programa planteó la problemática central de la representación y estructuración del conocimiento, puesto que el número de parámetros a tener en cuenta
estaba también limitado. DENDRAL. que poseía un inmenso bagaje de conocimiento especializado tenla un grave inconveniente: el conocimiento propio del dominio estaba
integrado de fonna clásica en los mecanismos de razonamiento y , por consiguiente, la menor modificación de este conocimiento conlleva a costos computacionales de actualización muy
elevados. Por estas razones se impuso la necesidad fundamental de separar el conocimiento de los mecanismos de razonamiento.
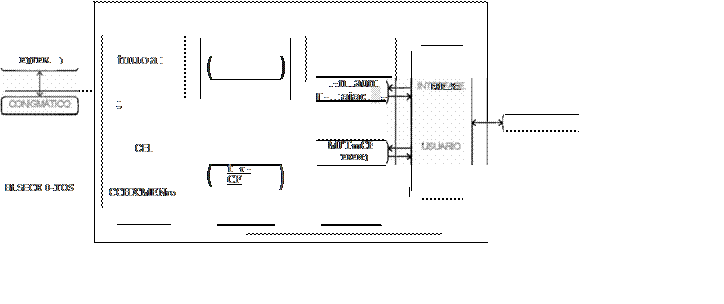
La arquitectura de un SE (Figura 1) está organizada alrededor de tres elementos principales:
a) Base de conocimientos. Estructuras de datos que contienen el conjunto de conocimientos especializados Introducidos por el experto del dominio. Se pueden asociar a una memoria pennanente, están fonnadas por objetos, relaciones, casos particulares, excepciones, estrategias de resolución de problemas. condiciones de aplicaclón.
La constitución de la base de conocimientos es un proceso largo y delicado, puesto que es necesario extraer ese conocimiento del experto y transferirlo al SE. Este proceso constituye un dominio de Investigación muy Importante, denominado cognimátíca o ingenierla de conocimiento.
b) Motor de inferencias. Es e! núcleo de! sistema, ya que pone en acción los elementos de la base de conocimiento para construir los razonamientos. Ejecuia las deducciones en el curso del proceso de resolución.
c) Base de hechos. Memoria auxiliar que contiene a la vez los datos del usuario (hechos iniciales que describen el enunciado del problema a resolver) y los resultados intennedios obtenidos a lo largo del
procedimiento de deducción.
Además de estos tres elementos. se incluyen los siguientes módulos de interfase :
Interfase de usuario o sistema de consulta.
Módulo de explicaciones, el cual permite trazar el camino tomado en el razonamiento.
Módulo de adquisición de conocimiento.
SISTEMAS EXPERTOS DE TIPO "SENTIDO COMÚN"
Los tipos de conocimiento que son representados y utilizados en los SE, tradicionalmente son de 3 clases:
![]() 270
270

![]()
![]()
![]() CE
CE
![]()
![]()
![]()
![]() a:tO: MEN!O
a:tO: MEN!O
![]() Figura 1.Arquitectura de un Sistema Expeno.
Figura 1.Arquitectura de un Sistema Expeno.
a) Conocimiento con reglas rígidas, el cual es fijo, como serta el SE desarrollado por Digital para ensamblar los diferentes tipos de máquinas VAX que ellos construyen, de tal forma que no falten piezas o partes de equipo (1). Los sistemas normalmente asesoran a los usuarios dando información complementarla, como en este caso qué es una máquina VAX y cómo opera. Este conocimiento normalmente viene de los manuales de operación y ensamblado de la máquina.
b) SE con conocímierrfo experiencia/, o sea, situaciones donde algunos expertos han acumulado una gran cantidad de conocimiento y éste ayuda en ciertas tareas o situaciones. Un ejemplo típico, es el sistema de la General Electric para el diagnóstico de descompostura de locomotoras. Este conocimiento normalmente se obtiene de personas con mucha experiencia en el área específica de trabajo.
e) Conocimiento con bases de datos de tipo probabillstico. En este caso, el conocimiento está fuertemente marcado por valores de probabilidad o. en los casos más recientes, por anállsis de probabilidad condicionales encadenados (2-4).
Sin embargo, el conocimiento que utilizan los humanos en la vida diaria, -en una gran
cantidad de situaciones.. no es conocimiento fijo o exacto ni tampoco es probabilfstico, en algunos casos, está dado por la experiencia - pero no por la experiencía individual, sino por la experiencía socíal-. A este tipo de conocimiento se le llama en las ciencias sociales, conocimiento de "sentido común". Si bien en una primera aproximación pareciera ser que esta forma de conocimiento no es tan importante como lo es el "preciso" de las ciencias Ffsicas o lngenierla; desde otro punto de vista, este conocimiento determina el comportamiento de los humanos. Por ejemplo, el comportamiento político, ya sea en situaciones especificas -como sería la conducta de voto- o un poco m.és en general, en las ideas polfticas de los grupos o personas.
En esta situación el conocimiento no es de tipo factual, sino que es una integración de hechos factuales. chismes. actitudes, atribuciones, prejuicios, valores éticos, etc., los cuales detennlnan un conocimiento polltlco de sentido común. Este conocimiento obviamente es diferente al que poseen las ciencias políticas, el et1al es más preciso y exacto. Como se puede ver en este ejemplo, este conocimiento de "sentido común" es una suma muy extrana de experiencias y de datos generados en la sociedad; en la vida diaria y en
la sociedad contemporánea, este conocimiento
![]() 27 1
27 1

tiene grandes efectos en la sociedad, y en muchos casos en la ciencia.
Otro ejemplo Interesante de conocimiento de sentido común, es el que tienen los grupos especfficos de lo que es la "enfermedad", el cual es muy diferente al conocimiento médico exacto (5). Muy conocidos son los casos, en donde los sujetos están técnicamente enfermos, pero si no se dan cuenta o están motivados por algo especial y dado que su concepción de •sentirse enfermo· es diferente pueden desarrollar sus actividades normales, aún con síntomas como temperatura elevada y otras molestias.
En la lteratura técnica contemporánea , ha habido una fuerte discusión, ya que esta clase de conocimiento parece ser substancialmente diferente al conocimiento que se trabaja tradiciona lmente en los SE (6-7).
Uno de los aspectos más Importantes es que, en el conocimiento de los SE tradicionales, las lógicas que se utilizan están fuertemente ancladas en las lógicas formales que conocemos, como es la lógica matemática normal, la lógica borrosa (fuzzy logic), la bayesiana, etc.
En cambio, la lógica que está embebida" en el conocimiento de sentido común, está más marcada por relaciones de información que en
muchos casos pueden ser arbitrarias, y no por una lógica clásica. Sin embargo, es indudable
qu. existe una "lógica" del conocimiento de sentido común, la cual está dada por las estructuras de conocimiento y no por una meta· estructura formal o semi formal. A este tipo de lógica, que tiene reglas muy especiales y
diff clles de estudiar, se le ha denominado "lógica natural" (8-1O).
Por lo anteriormente expuesto,se considera que una aproximación útil en la creación y desarrollo de SE, que operen con conocimiento
de sentido común,es la teorla clásica de "redes semánticas· desarrollada por Colllns & Quillian en 1989 (11), en la cual el significado está representado por redes de conceptos que tienen diferentes formas de conexión entre sus elementos o nodos. Esta teoría ha tenido una fuerte parte computacional que en general es conocida como teorla de "frames• (marcos) . Por otro lado, el desarrollo de las redes semánticas artificiales -en particular en la teorfa
de Para/le/ Dístributed Proressíng (POP) (12)-, ha sido la base de la Neurocomputac lón moderna.
Tanto en la creación de SE clásicos como en la moderna Inteligencia Artificial (1.A.) basada en las Neurocomputadoras; la teoria y procedimientos de las "Redes Semánticas· (R.S.) han sido un aspecto que los clentificos computacionales han descuidado, siendo que una de las partes más importantes del origen
de estos trabajos se encuentra en los intentos, a fines de los años 70's, por crear teorías
f-Orrnales de cómo se representa o almacena el significado en los humanos. Los orígenes teóricos de este tipo de trabajos fueron dados por el mismo Von-Neumann, uno de los padres de las computadoras clásicas, quien estudió, por un lado, los Autómatas Celulares y por el otro lado, las posibilidades de computadoras basadas en el supuesto funcionamiento del cerebro humano (13).
En el presente trabajo, se presenta un breve resumen de la teoría de las R.S., así como la
implementación de un procedimiento específico para elaborar bancos de datos relacionales, con especial énfasis en los pasos especfficos que se tienen que realizar para la creación de estos bancos de información, en SE clásicos y neurocomputacionales, de tipo "sentido común".
LA TEOR(A Y TÉCNICA DE LAS REDES SEMÁNTICAS NATURALES
En los trabajos sobre representación del conocimiento en humanos, a fines de los anos 60's, surgió la teoría de "Redes Semánticas"; esta teoría afirma que el conocimiento está dado por nodos de información y la relación que existe entre esos nodos. En los años recientes, se han Implementado una gran cantidad de sistemas de representación de información en l.A., en cuya construcción se utiliza esta teoría. Por ejemplo, PROSPECTOR es uo SE, desarrollado en 1974 en la Universidad de Stanford por Duda & Konolige, especialistas en prospección minera. El programa ha obtenido resultados espectaculares, puesto que ha sido capaz de deducir que una parte del depósito de pórfido de molibdeno, ya explotado , debla encontrarse en otro yacimiento que los geólogos no hablan sabido detectar hasta entonces (este
![]() ?72
?72

yacimiento estaba valorado en cientos de millones de dólares).
Ya mencionamos que la evolución computacional de las R.S. es la Teoría de frames. Sln embargo, existe una distinción teórica muy importante, entre la forma de representación en sujetos humanos y su
implementación en teorfa computacional. Esta distinción consiste en que: en la teorfa de redes, se habla de nodos, relaciones y otros tipos de procedimientos de interacción de la información; en su forma ortodoxa, esta teorfa estaba hablando de procesamiento paralelo y es una de las bases de lo que hoy conocemos como neurocomputadoras . En cambio, en la teoría de frames, se habla de stacks, apuntadores, slots o posiciones y f;Jfers; lo cual da una gran ventaja para su Implementación en un sistema computacional con un solo procesador.
Sin embargo, el desarrollo de las "redes semánticas naturales· (RSN), esto es, el conocimiento derivado directamente de las formas de almacenar y relacionar información de los humanos, ha sido escaso. El modelo de RSN, fue publicado en 1976 por Figueroa y
otros Investigadores, y a. partir de este trabajo
original, en Latinoamérica ha habido un fuerte desarrollo de esta clase de modelos, y en la actualidad hay más de 250 trabajos publicados con esta aproximación.
Se ha mostrado experimentalmente que estas RSN obtenidas mediante estos procedimientos, son muy confiables en su forma de representar el conocimiento de grupos espedficos (14-18). Se han hecho una gran cantidad de estudios utilizando estas técnicas, en particular la Investigación en la Psicología Social Experimental, ha permitido validar las redes semánticas natura les (19).
EL PROCEDIMIENTO DE CONSTRUCCIÓN
DE UNA RSN
En general, desde esta perspectiva, la Investigación experimental desde sus comienzos, se puede organizar en dos grandes grupos, en donde independientemente del modelo que se utilice se encuentra que la forma como se trabajan las redes es: a) por medio de claslflcaciones o taxonomias
artificiales, como en el caso de Collins y
Quillian (11),que es una taxonomía biológica o
b) por medio de listas de atributos o relaciones que el investigador presupone es una red semántica, como en el caso de Norman y Rumelhart (20).
En su forma esencial (16) la teorla de redes semánticas postula que la infonnación contenida en memoria a largo plazo está organizada en forma de redes de información, en donde las palabras o eventos forman relaciones "naturalesft, las cuales como conjuntos de palabras (sets) sirven para conformar el significado. Asf. por ejemplo, la palabra MANZANA está relacionada en una red con las palabras: rojo, fruta, árbol, redondo, dulce, etc.
Para realizar estos estudios se requiere desarrollar una técnica que en primer lugar penníta obtener cuáles son los elementos de la red y en segundo lugar que pueda describir en forma cuantitativa cuáles son las relaciones entre los elementos. Figueroa et al (15) han elaborado formas simples y efectivas de cuantificar diferentes aspectos de la red: riqueza, densidad, distancia entre conceptos, consenso entre grupos, consenso de cada individuo con su grupo, etc.
El término "natural• se refiere a que los nodos o definidoras, al ser generados por los sujetos (y no presupuestos por el Investigador) penntten conocer cómo es que los sujetos organizan la infonnación en su memoria. Sin embargo, en este modelo las relaciones están determinadas solamente por la distancia entre
los nodos y se restringen a ser "definidor de" o "definido por" otros al mismo tiempo (aspecto activo del proceso de manipulación con la información en Memoria (reconstrucción)). A continuación se presenta una descripción de la manera de obtener "redes semánticas" , asf como las caracterfsticas de su implementación en un sistema computacional de tipo SE.
I M PLEMENTACIÓN COMPUTACIONAL DEL SISTEMA
El sistema captura, de sujetos humanos, la Información acerca de la temática con la que se pretenda fonnar la base de conocimientos. La operación se realiza en tres etapas:
![]() 273
273

_'i 1. En esta primera etapa, el investigador decide el área que le interesa estudiar y Jos conceptos más relevantes de la misma (se recomienda 20 a 30 conceptos} . Por ejemplo , si se desea conformar una base de conocimientos politices, podrla elegirse la siguiente lista de conceptos: Poder, Negociación, Democracia, Izquierda, Gobierno, Representantes, Libertad. Elecciones, Acuerdos, Justicia, Gobernante, Política, Ciudad, Presidente, Dedazo.
· El sistema pide a cada uno de los sujetos que definan los conceptos presentados, y con las respuestas va formando la base de datos sobre el tema en particular. En la figura 2 se presenta ei diagrama de flujo correspondiente a esta etapa. El procedimiento consiste en definir estos conceptos por medio de sustantivos, adjetivos, verbos o adverbios, pero sin utilizar articulas, preposiciones ni alguna otra partlcula gramatical. Después de que los sujetos anotan todas las palabras definidoras de cada concepto, se les pide que las jerarquicen, es decir, que anoten el número
1 a la palabra que mejor defina el concepto, el número 2 a la que lo haga en segundo lugar, y asi sucesivamente hasta agotar todas las palabras definidoras de cada concepto. Se les proporcionan ejemplos como el siguiente:
Concepto:
MANZANA
Definidoras:
rola (2), fruta (1). árbol (3). dulce(4).
donde: el número indica el orden de jerarquización que ocupa cada definidora (bloque 1 de la figura 2).
Con estos datos obtenidos con poblaciones de sujetos humanos, el sistema depura la
información (por ejemplo: errores ortográficos, sinónimos, género de la palabra definidora, plurales, etc.) y obtiene las redes de
conocimiento de las temáticas específicas (bloque 11 de la figura 2). A partir de esta
información, se pueden calcular diferentes valores cuantitativos, que permiten conocer algunos aspectos de la riquez.a semántica y de relaciones del conocimiento de los sujetos (bloque 111 de la figura 2):
1) VALOR J - Para cada concepto se enllstan todas las palabras definidoras
diferentes generadas por un grupo de sujetos y
se obtiene el número total de definidoras, es decir, se cuantifica la RIQUEZA DE LA RED.
2} VALOR M - Se obtiene una matriz de doble entrada en donde las columnas corresponden a el orden de importancia (1o., 20., etc.) y los renglones a las definidoras
generadas. En cada casilla está la frecuencia de uso. Se realiza una operación para obtener una puntuación para cada definidora (PESO SEMÁNTICO) que pondere el valor de frecuencia de mención con la importancia asignada a la misma. Este sistema de puntuación permite cuantificar y diferenciar la importancia que dan los sujetos a cada una de las palabras definidoras en la red semántica generada para un concepto específico .
3) CONJUNTO SAM - es el grupo de las 1O definidoras de valor M más alto, generadas por un grupo para cada concepto, y cons1ituye la RED SEMÁNTICA base de tal concepto (bloque IV de la Figura 2).
4) VALOR FMG - se toma el conjunto SAM para cada concepto y a la primera palabra definidora -es decir, a la de valor M más alto se le asigna un valor de 100% y se determina el porcentaje de las siguientes palabras definidoras con respecto a la primera. Este valor permite cuantificar la distancia entre las palabras.
Durante esta etapa, el sistema va a conformar una o varias bases de datos, en donde cada una de és1as tiene una serie de valores cuantitativos que lo representan.
ET"-P..\ j, En esta etapa, hay varias alternativas que se pueden seguir para utilizar el sistema, la más importante es analizar las redes semánticas y emplearlas como predictores de eventos, con base en el conocimiento que está en la red. Por ejemplo, en ciertas redes de conceptos politicos en México y en Venezuela, se ha vis1o que és1os son un claro predictor de acciones políticas contra el Gobierno (21, 22).
otra alternativa es comparar el conocimiento individual de un sujeto en particular, con el del grupo total y ver que tanto se aproxima o aleja de él, en forma cuantitativa y cualitativa (23). Una opción distinta es comparar redes de diferentes grupos sociales;

en esta misma forma se puede ver la evolución de las redes de conocimiento de diferentes grupos (18).
Dado que la tercera etapa está dada por un sistema relacional, es posible obtener las redes de diferentes grupos mezclados en forma de bases de datos relacionales.
DESARROLLO AUTOMÁTICO DEL SISTEMA EXPERTO PROPUESTO
En Jos al'\os recientes, ha habido un desarrollo substancial de toda una subdiscipllna que es conocida como "machine leaming• (máquinas que aprenden) (24), la cual, al igual que la Neurocomputación, no es nueva y se han reportado diversos trabajos (25), en los cuales se fundamenta esta subdísciplina. La idea principal en·machine leaming• y asr mismo su meta, es encontrar y definir en forma precisa, algoritmos matemáticos o computacionales que permitan que una máquina "aprenda"; esto es, que reduzca el número de errores con el paso
del tiempo y que aumente o extraiga información de s•.1 experiencia de funcionamiento. Existe! ·:deas teóricas de cómo formalizar estos modelos de aprendizaje en máquina, el más conocido es el de Valiant (26, 27).
Sin embargo, existe otra alternativa a la de los algoritmos de aprendizaje específico, que
está relacionada con la idea neurocomputaclonal de que es la estructura de
la computado ra -que está cableada en una forma particular (un paradigma neurocomputacional)- la que determina el aprendizaje. Lo que aquí se propone es que la forma de extraer, la forma de ir almacenando y la forma de ir clasificando los datos en una situación de RSN, es en si un paradigma de "machine leaming" , con la diferencia de que el algoritmo es més que todo un procedimiento sencillo de interrogación, análisis de frecuencia, y almacenamiento de la información, y el resultado es un SE restringido, de tipo "sentido común".
![]()
![]()
![]() ETAPA i
ETAPA i
![]() ETAPA I!
ETAPA I!
ETAPA 111 [
 Caura w ptos y lw
Caura w ptos y lw
defmldoraa P' P"f
oll rirupo ·x·
Nuew información p

![]()
![]()
![]() .JdiflOll' lo base de c... nahlral" del gn.ipo •
.JdiflOll' lo base de c... nahlral" del gn.ipo •
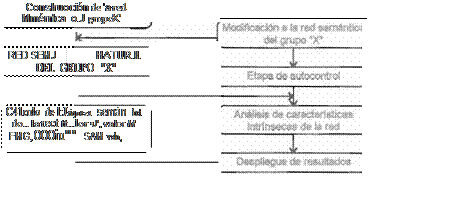 Figura 2.Implementación en una computadora de un sisiema utomátlco pura generar Sistemas Expertos de tipc ''sentido común".Modo d creación y
outocontrol de 1 redsemántica de un grupo "X".
Figura 2.Implementación en una computadora de un sisiema utomátlco pura generar Sistemas Expertos de tipc ''sentido común".Modo d creación y
outocontrol de 1 redsemántica de un grupo "X".
![]() 275
275

CARACTERISTICAS GENERALES DEL
SISliEMA
Estos SE de sentido común, construidos con la teorf a de RSN, tienen varias propiedades Intrínsecas a su desarrollo e implementación que los hace especiales, y al mismo tiempo muy atractivos:
a) Nos permiten trabajar con la semántica "natural• debido a que las redes de conocimiento, están definidas por sujetos humanos en su uso diario (contextuaQ, en donde el significado está dado por una serie de nodos e Interacciones de diferentes tipos entre
los nodos o conceptos.
b) La forma de manejo de este conocimiento es de tipo inductivo (frecuencial).
e) Esencialmente, son sistemas que en forma automática van presentando a los
sujetos una serie de conceptos, los cuales se tienen que definir y automáticamente se
desarrolla el análisis y forma la base de datos y relaciones. Es decir, el aparato definidor es un sistema que aprende constantemente, a
medida que va incorporando nueva información a las redes (sistema de aprendtzafe automático).
d) Su comportamiento es estadístico, y la definición de un concepto se va haciendo más segura (esto es, su lista de definidoras), en cuanto más sujetos se Interroguen;pero a partir
de un cierto momento, si el grupo de sujetos no cambia, la lista de definidoras se estabiliza.
e) Un cambio en la base de datos central, sólo puede ser dado por un cambio substancial del tipo de sujetos que son interrogados. En una situación sencilla, si se trabaja con tipos de sujetos que pertenecen al mismo grupo de referencia -desde un punto de vista social-, el comportamiento del sistema de base de datos es muy estable. Pero si se cambia de grupo de sujetos, el comportamiento de la base de datos puede ser diferente; y se pueden generar parámetros numéricos y conceptuales, que marquen la diferencia entre los grupos; un ejemplo, se sabe que grupos de Ideología diferente, van a generar bases de datos diferentes (21).
f) En determinadas situaciones, permite su utilización para distinguir entre sujetos
"expertos· vs. sujetos "novatos , con base en la comparación de las redes semánticas y de cercano o lejano que su definición esté de la red "correcta•.
g) Debido a las caracteristlcas de estos SE, son muy poco eficientes cuando se trabaja con conceptos técnicos, por ejemplo, conceptos de la Física o de la Ingeniarla; y son muy efectivos
y se muestra su potencia, cuando trabajan con
conceptos de tipo experiencia!. Por ejemplo los conceptos de gobierno, estado, progreso. amor y enfermedad, son conceptos en los cuales estos sistemas trabajan muy bien y nos generan listas muy claras y precisas de la definición que dan diferentes grupos sociales. En este sentido, estos SE son de sentido común.
h) Este sistema trabaja en una situación de "aprendizaje simb<Jlíco• (symbolic /eamíng), ya que la relación entre la forma en que se representa y el objeto o fenómeno a representar, es totalmente arbitraría; lo cual, desde un punto de vista computacional y de la l.A.. tiene algunas ventajas y algunas desventajas (28).
i) El contenido de estos SE es fácil de entender por los humanos y a esto, Mlchalsky (29,30) le ha llamado ·co mprehensibility principie•, y él seilala que es muy importante en la teorfa de machine Jeamlng.
j) Es posible obtener una gran cantidad de parámetros cuantitativos de estos SE, lo cual nos permite la poslbllldad de desarrollar trabajo emplríco y de investigación.
k) El comportamiento de la base de conocimientos está regulado por una situación de autocontrol estadlstico, ya que es el análisis de frecuenc ias el que regula todo su comportamiento (es decir, la estructura de información contenida en la base de conocimientos se va automodificando y autocorrigiendo). Las definidoras que un sujeto da a un concepto, sólo tienen sentido cuando son analizadas en relación con todo el grupo; y son las definidoras dadas por la mayorla de los sujetos, las que definen los conceptos de la red, y un sujeto individual no los puede cambiar.
![]() 276
276

CONCLUSIONES
La técnica aqui descrita permite crear bases de datos naturales, tomando como criterio el conocimiento de los humanos, y al mismo tiempo nos da una serie de criterios cuantitativos que nos permiten optimizar la
utlllzaclón y organización Interna de bases de
datos complejas. Esta técnica está firmemente anclada en las teorías y técnicas que dieron origen a las nuevas formas de l.A.; es decir, a los sistemas coneccionistas o neurocomputadoras (31). Es importante sei'\alar que una de las características que le dan poder a este tipo de sistemas es su flexibilidad y en el desarrollo de cualquier SE esta caracterlstlca se tiene que conservar.
Eltomar uno de los mayores desarrollos que ha habido en la teoría de memoria humana compleja, la teorla de R.S., puede ayudar en una forma específica a desarrollar formas e instrumentos para el estudio de los contenidos de conocimiento de los sujetos y de la organización del mismo, lo cual puede tener como consecuencia un impacto importante en la investigación en estas áreas de conocimiento.
Las redes así estudiadas permiten conocer cómo está representada y organizada la Información en los sujetos, entender cómo se puede integrar nueva información a la ya almacenada y establecer nuevas relaciones. Este dinamismo de las redes permite explicar su constante cambio y enriquecimiento; nos abre, asimismo. la posibilidad de utilizar este conocimiento sobre la organización en Memoria en la creación de bancos de información de SE basados en conocimiento "real" de sujetos humanos (32). La ventaja adicional de utlllzar datos directos obtenidos en sujetos humanos,
es la posibilidad de introducir relaciones y
definiciones de tipo 1ógica borrosa• (fuzzy) (33,34). o sea, natural y de contar con un procedimiento de autoaprendizaje de las redes de Información que conforman la base de conocimientos.
SI requiere mayor lnforrnación, dirljase a la siguiente dirección electrónica: evargas@sparccl ulsa.ulsa.mx
RE F E RENCIAS
1. Levlne, R y Drang, D. Al and Expert
Systems. USA. Me. Graw-Hill.1990.
2. Cheeseman P. A method of computlng generalized Bayesian Probability values for Expert Systems. Proc. 8fh lntemational Joint-Conterence on Artificial lnte/llgence IJCAl-83 . Karlsruhe. 1983.
3. Pearl, Judea. Probabilistíc Reasoning In lnteffígent Systems. USA. Morgan Kaufmann. 1988.
4. Neapulitan, Richard E. Probabilistic Reasoning In Experl Systems. USA. Wiley lntersclence. 1990.
5. Figueroa Nazuno, J. y Vargas Medina. E. La representación social de salud y enfermedad en diferentes grupos sociales: una aproximación soclológica a la salud.
Cuarto Seminario de Investigación Educativa en Ciencias de la Salud, e.u.,
México. 17-19 de nov. 1987.
6. Buchanan B. y Shortliffe E. Rulebased Experf Systems The MYCIN Experiments . USA. Addison Wesley . 1984.
7. Galnes, B. y Boose, J. Knowledge Acquisdion for Knowledge-Based Systems. USA. Academlc Press, vol. l. 1968.
8. Nolt, J. E. lnfonnal Loglc Posible Worlds and Jmagination. USA. Me. Graw-Hill. 1984.
9. Olgu[n Ramírez. G. y Figueroa Naz.uno, J. Solución de problemas sociales: un análisis en cognición social. IV lntemational Conference of Thinking, San Juan, pto. Rico, 17-20 august. 1989.
10. Vargas Medina. E. Solución de problemas sociales y su fundamentación con lógicas naturales. /1 Seminario de Procesos Cognoscitivos, C. de Instrumentos, UNAM, Marzo. 1991.
11. Coltins, A. K. y Quíllian • M. R. Retrleval type for semantic memory. Joumal of
![]() 277
277

verbal leaml ng a nd verbal behavlor, 6, 240-
4 7. 1969.
12. Rumelhart, O. E., McClelland, J. L. y The POP Research Group. Para/le/ Dístributed Processing. Explorations in the microstructure of cognition, vols. 1 y JI. USA. The MIT Press. 1986.
13. Von-Neumann, J. The computer and the brain. New Haven and London. Yale Universíty Press. 1958.
14. Figueroa, J. G., Gonzále:z., E. y Solfs, V. M. An approach to the problems of meaning: Semantic Network. Joumal of Psyoholinguistical Research, 5, 2, 1076-
1115. 1976.
15. Figueroa, J. G., Carrasco , M., Sanniento, C., Acosta, M. y López, H. Una aproximación en la enseí'lanza de la Física basada en la utilización de redes semánticas. VII Congreso Nacional de Ensellanza de la Flsica, Morelia, Mich. Noviembre, 1981.
16. Figueroa, J. G., Carrasco, M. y Sanniento,
C. Sobre la teoría de redes semánticas . IV Encuentro Nacional y I Latino-americano de Psico/ogfa, Guadalajara Ja!. Mayo. 1982.
17. Figueroa, J. G. La Teoría Formal M.l.S. de Representación Semántica y de
conocimiento. 11 Seminario de Procesos Cognoscitivos, c. de Instrumentos , UNAM,
Marzo. 1991.
18. Vargas Medina, E. y Calzada Ugalde, C. Evolución de la representación conceptual de la física en estudiantes universitarios y preuniversitarios. Revista del Centro de Investigación, vol 1, No. 2, Universidad La Salle, enero, 49-62 . 1994. ·
19. Vargas Medina, E. y Figueroa Nazuno, J. Redes semánticas como medida de actitud, IV Congreso Mexicano de Psicologfa, 15-19 de nov. 1985.
20. Norman, D. A., Rumelhart, D. E. y The LNR Research Group. Explorations in Cognition. San Francisco. Freeman. 1975.
21. Zamudio Grave, P., Lópe:z. Méndez, M., Bolai'tos Trujano, R., Vargas Medina, E. y Figueroa Nazuno, J. Sobre la representación de eventos politícos en diversos grupos del D.F. Primer Foro Nacional de la SOMEPSO, México D.F., 25-27 de septiembre. 1986.
22. Mota Botella, G. y Sanders Brocado, B. Identidad del hombre y la mujer mexicanos: crisis y perspectivas ante el siglo XXI, Fundamentos y Crónicas de la Psicologfa Social Mexicana, Af'lo S. Números 8 y 9, 61-71.1992.
23. Lopez Ramfrez, E. o. y Ramos Espinosa,
M. T. Sistema predictor de Indice Reprobatorio S.P.l.R. vol. 2: Modelo cognitivo y computacional. México. CISE, UNAM. En prensa.
24. Tsypk.in, Y.Z. y Nik.olic, Z.J. Foundations of the theory of Leaming systems. USA. Academic Press. 1973.
25. Nilsson, N. J. Leaming Machines. USA. Me. Graw-HiU. 1965.
26. Valiant, L. G. A Theory of the Leamable. Artificial lnte//igence and Language Prooessing, Vol 27, # 11, November. 1984.
27. Vargas Medina, E. y Aguilar Cornejo, M. lnducting Knowlegde for expert system based in machine leaming algorithms. Proceedings of Eighf fnfemafional Conference: The computers in the ínstitutions of education and of researoh, México City, october, 1992:291-300.
28. Davis, E. Representations of Commonsense Know/edge. USA. Margan Kaufmann Pub. 1990.
29. Michalski, R. s.. Carbonell, J. G. y Miche!I,
T. M.Eds., Maohine Leamíng: An Artificial fnta/ligence Approach. Tioga, Palo Alto, Callf. 1983.
30. Michalski, R. s. y Kodratoff. Y. Machlne Leaming, vol. 111. USA. Margan & Kaufmann. 1990.
31. Vargas Medina, E. Modelos teórico experimentales de representación de
![]() 278
278

conocimiento en sistemas naturales humanos y artificiales redes neuronales. Disertación Doctoral, Universidad La Salle, en proceso.
32. Vargas Medina. E., Martrnez Casas, G. y Hemández Martínez, E. Natural Semantlc Networks: Too! for implementing Common Sense Knowledge Bases.Procee<iings of Seventh lntemational Conference: Tñe Computers in the lnstifutions of Education and fhe research, Mexico City , october, 264-271. 1991.
33. Zadeh, L. PRUF: A meanlng representat lon language for natural language. In: Gaines,
B.R. ed. Fuzzy reasoning and its
aplications. USA. Academ ic Press. 1981.
34. López de Mántaras, R., Cortés, U., Plaza, E., Sierra, G., y Villar, A. MILORD: An essencial system for expert systems based on fuzzy reasoning. In: C . V. y Prade eds. Fuzzy /ogics in knowledge engineering. Germany. TUV Rheinland GmbH. 1986 .