Introducción
La depresión, según la Organización Mundial de la Salud (OMS) (Organización Mundial de la Salud, 2021) es un trastorno mental común caracterizado por episodios de estados de ánimo deprimido o pérdida del interés en actividades, la mayor parte del día, casi todos los días o durante al menos dos semanas. Además de ser la principal causa de discapacidad a nivel mundial (OMS, 2021), los trastornos depresivos también forman el principal grupo de psicopatologías que contribuye a las muertes por suicidio (Yomaira, 2021). A nivel mundial, se reporta que 280 millones de personas viven con depresión (OMS, 2021). En México, el porcentaje de la población con síntomas de depresión se ha estimado en 15.4% (19.5% en mujeres y 10.7% en hombres) (Instituto Nacional de Estadística y Geografía, 2021).
Además de los datos previamente presentados, se ha reportado un aumento en la prevalencia de sintomatología depresiva a partir de la pandemia por COVID-19 (Nicolini, 2020; Santomauro et al., 2021), estimando que los casos de depresión mayor en el mundo han tenido un aumento aproximado del 28% (Santomauro et al., 2021). De hecho, durante el primer año del desarrollo de la pandemia por COVID-19 en 2020, el 64% de adolescentes en países de habla hispana presentaron síntomas de depresión (27.7% depresión leve, 15% depresión moderada, 10.3% moderadamente-severa, y 10.8% depresión severa) (Masse, 2022).
Se sabe que la depresión se puede presentar en cualquier periodo de la vida, siendo el inicio común de la enfermedad en edades tempranas, como en la niñez y la adolescencia (Acosta et al., 2011), y puntualmente con un establecimiento durante la etapa de la adolescencia en el caso del trastorno depresivo mayor (Mori, 2013). En la extensión de la bibliografía que documenta los trastornos depresivos, existen diferentes clasificaciones. Por un lado, la OMS señala que hay diferentes categorías en el espectro de los comportamientos depresivos (OMS, 2021). De forma distinta, en APA (American Psychiatric Association, 2018) los trastornos depresivos se pueden clasificar según la naturaleza de los síntomas y su etiología: trastorno de depresión mayor, trastorno depresivo persistente (distimia), trastorno disfórico premenstrual, trastorno depresivo inducido por una sustancia/medicamento, trastorno depresivo debido a otra afección médica y otros trastornos depresivos especificados y no especificados. Particularmente, el trastorno depresivo mayor se caracteriza por la pérdida del interés, estado de ánimo irritable o triste, sentimiento de inutilidad o culpa, deterioro cognitivo, fatiga y alteraciones en los hábitos de sueño (American Psychiatric Association’s, 2018). Puede ser considerado como una condición de urgencia para la atención y prevención del suicidio, pues es la segunda psicopatología con mayor prevalencia de intentos de suicidio (31%) y suicidios consumados, luego del trastorno bipolar (Yomaira, 2021). La depresión afecta cada vez más a los jóvenes, y como una de sus consecuencias, las altas tasas de suicidio en los últimos años han colocado al éste como la cuarta causa de muerte en poblaciones de 15 a 19 años (WHO, 2021).
Sabemos que la detección temprana y el tratamiento adecuado de trastornos mentales de las personas es un tema relevante. Se deben tomar en cuenta diferentes factores que minimicen los efectos psicológicos y psiquiátricos de la pandemia por COVID-19. Así pues, una alternativa utilizada en los últimos años es a través del análisis de sentimientos. Particularmente, a través del uso de redes sociales como Twitter, Facebook o WhatsApp, se han podido detectar posibles síntomas de depresión de personas que corren riesgo de sufrir este trastorno mental (Rodríguez et al., 2019; Rodríguez et al., 2021). Desde su inicio en 2006, Twitter ha tenido un crecimiento importante y ahora tiene una enorme presencia en nuestra sociedad, con más de 1,300 millones de cuentas creadas que actualmente generan más de 500 millones de tuits por día (WordStream, 2022). Este gran depósito de información respecto a la expresión escrita de sus usuarios, y particularmente acerca de su comportamiento diario (debido a la naturaleza de la plataforma), puede permitirnos observar frecuencias de conducta más próximas a la realidad que en otras redes sociales. Su popularidad en el internet es tal que se estima que el 39% de los usuarios de internet en México utilizan la red social Twitter (Martinez, 2020), formando una base de usuarios en el país, de aproximadamente 13.3 millones de usuarios (Degenhard, 2021). El crecimiento y preferencia del uso de Twitter por los habitantes mexicanos ha abierto una gran oportunidad para el estudio de sus usuarios en distintas áreas del conocimiento.
Así pues, motivados por el problema tan grave de salud pública hoy en día como es la depresión, el objetivo principal de este trabajo de investigación es el de identificar perfiles con indicadores del trastorno depresivo mayor en usuarios de Twitter en México a través del análisis de sentimientos durante el confinamiento por COVID-19, y así poder responder interrogantes como cuáles son las emociones básicas predominantes en estos perfiles y cómo se pueden clasificar éstos de acuerdo a un índice de riesgo a la depresión.
1. Metodología
En la literatura se han estudiado distintas emociones básicas; Robert Plutchik considera ocho emociones básicas: alegría, enojo, tristeza, miedo, sorpresa, aversión, confianza y anticipación (Plutchik, 1980). En este trabajo, tal como se presentó en la referencia Rodríguez et al. (2021), trabajaremos con el modelo de Plutchik y el Proceso Jerárquico Analítico (PJA). Este proceso fue introducido por Thomas Saaty (Saaty, 1980), y representa una herramienta eficaz para tomar decisiones complejas, el cual establece prioridades al reducir las decisiones complejas a una serie de comparaciones de criterios (en nuestro caso emociones) por pares. El PJA ayuda a captar aspectos tanto subjetivos como objetivos de una decisión, y así operacionalmente poder construir índices (Saaty, 2008). El PJA genera un peso para cada criterio de evaluación de acuerdo con la decisión del tomador de decisiones, el especialista; cuanto mayor sea el peso, más importante será el correspondiente criterio. En nuestro caso, para conocer los pesos que los especialistas en salud mental les otorgan a las ocho emociones básicas para las personas con trastorno depresivo mayor, se aplica el PJA mediante una encuesta, ya sea física o electrónica. Además, se calcula la consistencia de las decisiones de los expertos, es decir, para determinar si las decisiones han sido consistentes en sus evaluaciones. Saaty (2001) sostiene que cuando la Relación de Consistencia (RC) es inferior a 0.1, indica que los resultados están dentro de los límites recomendados, son consistentes y el proceso puede continuar. El RC está dado por $RC=\frac{ICG}{ICA}$, donde ICG denota el Índice de Consistencia Geométrica, el cual está dado por $ICG=\frac{\lambda max^{-n}}{n-1}$, donde $lambda max$ es la suma de los máximos eigenvalores, calculados para cada emoción y$n=8$ es el número de emociones básicas; e ICA denota el Índice de Consistencia Aleatoria dado por $ICA=1.98\frac{n-1}{n}$. Para más detalle de la obtención de los pesos para cada emoción básica se recomienda consultar Rodríguez et al. (2021). Los pesos obtenidos para cada emoción básica por el PJA los denotaremos por $w_i$, $i=1,..., 8$.
Por otro lado, para el análisis de sentimientos necesitamos obtener bases de datos tipo texto de Twitter. Se recopilaron datos de esta red social comprendidos en el periodo 1-Enero-2022 al 22-Junio-2022 y se consideran dos grupos: Depresivo y No depresivo. Para el grupo Depresivo se buscan tuits que tengan el texto “tengo depresión” inmerso, después se seleccionan los usuarios que utilizan con mayor frecuencia la palabra “depresión”. Se realiza una validación emocional de cada perfil, es decir, se verifica que cada perfil efectivamente cumpla con los indicadores depresivos según los clínicos encuestados. Finalmente, y tal como lo sugiere Martins et al. (2021), se eliminan los datos atípicos.
Para el grupo No Depresivo se eligen perfiles que hayan escrito la palabra “Bienestar” con las fechas indicadas anteriormente. Cabe señalar que no se sabe si las personas en este grupo realmente presentan el trastorno de depresión mayor.
Para el procesamiento del texto se consideraron los siguientes aspectos (Huerta-Velasco y Calvo, 2021; Marrocchi et al., 2019; Martins et al., 2021): tokenización (el texto se divide en tokens, que representan palabras, oraciones o párrafos), eliminación de ruido (incluyendo elementos como @, URL, hashtags, menciones y emojis, aunque reconocemos que estos últimos pueden servir como refuerzos emocionales en la comunicación digital), cambiar a minúsculas, quitar espacios en blanco, quitar la puntuación, quitar los números, quitar palabras huecas y quitar palabras genéricas en inglés y/o español.
De acuerdo con Martins et al. (2021) se analizaron tuits utilizando el paquete estadístico R y se obtuvieron sus pesos (normalización del número de palabras en cada emoción entre el total de palabras de cada perfil), estos pesos los denotamos como $n_i,i=1, ..., 8$ . Comparamos estos datos con los valores obtenidos por el PJA a través de la distancia euclidiana. Además, Martins et al. (2021) también sugiere que se debe encontrar la relación entre depresivos y no depresivos, por ejemplo, utilizando la matriz de correlación. Para esto, se deberán considerar tuits de los perfiles de los dos grupos y encontrar la correspondiente matriz de correlación.
Por otro lado, los clasificadores jerárquicos son métodos de organización de datos cuya finalidad es la de obtener clústers de información asociada entre sí por similitudes de los individuos (Gareth et al., 2013). A su vez, los subconjuntos se vuelven a clasificar dependiendo de las similitudes de estos subgrupos. De tal manera que, a partir de un grupo finito de datos, se puede llegar a una clasificación en varios niveles que contenga a cada elemento de la colección. La predicción de una respuesta cualitativa se conoce como clasificación de la observación, ya que implica asignar la observación a una categoría o clase. Para este estudio, se asume que el perfil emocional, $x=(x_1, ..., x_8)$, tiene una distribución gaussiana multivariada (o normal multivariada), con un vector de medias $\mu _k$ (con $k=2$, Depresivo o No Depresivo) y una matriz de covarianza común en todas las clases. El Análisis Discriminante Lineal (LDA por sus siglas en inglés) (Breiman et al., 1984) determina a cuál de las clases pertenece cada perfil. Así pues, con notación de 1 denotaremos al grupo Depresivo y con 0 al No Depresivo. En la Tabla 1 se presenta un ejemplo de esta codificación.
Tabla 1
Ejemplo de matriz de datos
|
Depresivo |
Alegría |
Confianza |
Miedo |
Tristeza |
Enojo |
Aversión |
Sorpresa |
Anticipación |
|
1 |
0.077 |
0.073 |
0.185 |
0.191 |
0.020 |
0.234 |
0.028 |
0.192 |
|
0 |
0.199 |
0.175 |
0.136 |
0.003 |
0.025 |
0.147 |
0.098 |
0.217 |
|
1 |
0.173 |
0.246 |
0.006 |
0.131 |
0.114 |
0.162 |
0.075 |
0.093 |
|
1 |
0.147 |
0.114 |
0.124 |
0.139 |
0.121 |
0.166 |
0.085 |
0.104 |
|
1 |
0.040 |
0.098 |
0.139 |
0.137 |
0.114 |
0.193 |
0.178 |
0.101 |
|
1 |
0.038 |
0.136 |
0.034 |
0.207 |
0.181 |
0.215 |
0.149 |
0.040 |
|
1 |
0.073 |
0.070 |
0.209 |
0.112 |
0.215 |
0.132 |
0.145 |
0.044 |
|
1 |
0.188 |
0.057 |
0.141 |
0.090 |
0.133 |
0.081 |
0.200 |
0.110 |
|
1 |
0.021 |
0.099 |
0.131 |
0.082 |
0.207 |
0.053 |
0.166 |
0.240 |
|
0 |
0.101 |
0.119 |
0.009 |
0.198 |
0.099 |
0.141 |
0.216 |
0.118 |
Nota: Elaboración propia.
Para realizar una clasificación de los usuarios de Twitter que posiblemente tengan trastorno depresivo mayor se calculará un Índice de Riesgo a la Depresión (IRD), dado por el cuadrado de la norma euclidiana entre el vector de pesos $w_i$ obtenido por el PJA y aquellos pesos obtenidos por cada perfil $n_i$ (recordemos que éstos últimos se obtienen a través del análisis de sentimientos, donde $n_i$ es el número de palabras en cada emoción entre el total de palabras), es decir,
|
$$ IRD=\sum_{i=1}^{8}(w_i-n_i)^{2} $$ |
Note que el IRD es un índice que toma valores entre 0 y 1, pues para $i=1$, tenemos que $0< w_i, n_i< 1$ y además se cumple que $\sum_{i=1}^{8}w_i= \sum_{i=1}^{8} n_i=1$. Entre más cercano a 0 sea el IRD significa que tiene más depresión, en cambio, si el IRD es cercano a 1, el riesgo de tener depresión es menor. Tal como lo sugiere Martins et al., (2021), en este trabajo utilizaremos los clasificadores Naive-Bayes, Máquinas de Soporte Vectorial (SVM por sus siglas en inglés), nnet, Análisis Discriminante Lineal (LDA por sus siglas en inglés) y vecinos más cercanos (kknn) para clasificar los perfiles de acuerdo con su IRD.
2. Resultados
Se realizó una encuesta a 20 expertos de salud mental1 del estado de Aguascalientes, haciendo uso del método Delphi2 que permite determinar variables de acuerdo con su nivel de consenso y la jerarquización de su trascendencia (Reguant y Torrado, 2016). El $ICG$ fue de 0.1367984, mientras que el$ICA$ de 1.485, resultando una relación de consistencia de $RC=0.09212016< 0.1$. Los pesos ordenados para cada emoción resultantes mediante el PJA se presentan en la Tabla 2.
Tabla 2
Pesos asignados a cada emoción básica calculados por el PJA.
|
Tristeza |
Enojo |
Aversión |
Miedo |
Anticipación |
Sorpresa |
Alegría |
Confianza |
|
0.37480 |
0.20787 |
0.14145 |
0.13409 |
0.05994 |
0.02913 |
0.02669 |
0.02603 |
Nota: Elaboración propia.
Respecto a la minería de sentimientos, a continuación, se describen los pasos que se siguieron en este trabajo:
- Se recolectaron 1336 perfiles que escribieron el texto “tengo depresión” en Twitter en el periodo de tiempo especificado en la Metodología.
- Un total de 505 perfiles utilizaron con mayor frecuencia la palabra “depresión”.
- Después de una validación emocional del perfil de cada perfil, obtuvimos un total de 194 perfiles.
- Se recopilaron los últimos 50 tuits de estos 194 perfiles. Se realizó un análisis de sentimientos (preprocesamiento de los textos) y se eliminaron perfiles con alegría mayor a 0.3 y confianza mayor a 0.37, considerados como outliers o valores atípicos (ver Figura 1); resultando una muestra final 156 perfiles para el grupo denominado Depresivo.
- Respecto al grupo No Depresivo, se encontraron 121 perfiles que escribieron con mayor frecuencia la palabra “Bienestar”. Se recopilaron los últimos 50 tuits de cada perfil.
Figura 1
Boxplot del grupo Depresivo con outliers
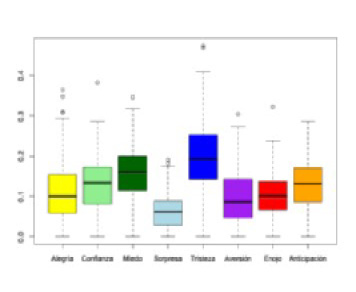
Nota: Elaboración propia.
En la Tabla 3 se muestran los porcentajes de hombres, mujeres y neutros en la muestra de Depresivos y No Depresivos; el término Neutro no hace referencia a un género, sino a perfiles pertenecientes a instituciones o empresas, mayormente gubernamentales, que no corresponden a personas individuales. Dado que el objetivo principal del estudio es identificar perfiles de personas con indicadores de trastorno depresivo, consideramos que estos perfiles institucionales no eran relevantes para el análisis. La exclusión de estos perfiles garantiza que el análisis se mantenga coherente con el objetivo del estudio, enfocándose únicamente en personas, lo que a su vez mejora la validez y relevancia de los hallazgos.
Los porcentajes obtenidos para el grupo Depresivo tanto de hombres como de mujeres resultan consistentes con aquellos que la literatura menciona (Saloni et al., 2021). Por otro lado, note que el mayor porcentaje en el grupo No Depresivo se encuentra en Neutro, pues fueron generalmente perfiles de empresas gubernamentales, estaciones de radio, televisión, etc.
Tabla 3
Porcentaje de mujeres y hombres en las muestras.
|
Depresivo |
No Depresivo |
|
|
Sexo |
(%) |
(%) |
|
Hombre |
32.8 |
22.0 |
|
Mujer |
67.2 |
17.0 |
|
Neutro |
0 |
61.0 |
Nota: Elaboración propia.
En la Figura 2 se presentan los pesos en cada emoción del grupo Depresivo y No Depresivo después de realizar un análisis de sentimientos de los tuits analizados.
Figura 2
Pesos en cada emoción del grupo Depresivo y No Depresivo.
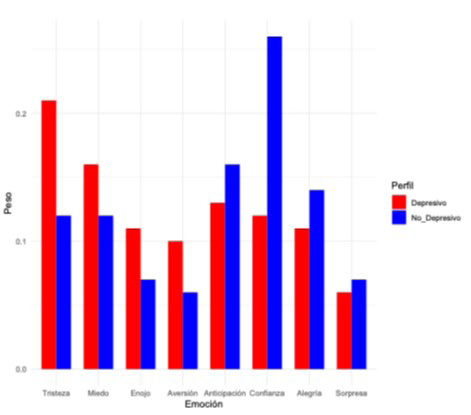
Nota: Elaboración propia.
Podemos observar que dentro del grupo Depresivo la Tristeza es la emoción con mayor peso, seguida de Miedo, Anticipación y Confianza. Note que esta última se considera una emoción positiva, de ahí que resulta interesante cómo es que los perfiles catalogados como Depresivos están resultando tener confianza. Alegría, Enojo y Aversión prácticamente tuvieron el mismo peso de 0.1, resulta interesante cómo es que Enojo no obtuvo un peso mayor en la muestra obtenida, de manera similar Aversión, pues se esperaría tendría mayor peso. Finalmente, Sorpresa obtuvo un peso menor. De manera general, se puede decir que los perfiles depresivos analizados no están escribiendo gran cantidad de palabras catalogadas como negativas, pues confianza y alegría resultan tener un peso muy similar al de enojo y aversión.
Se calculó además la correlación del grupo Depresivo y No Depresivo, capturado en la variable Clasificación (ver Figura 3) y las ocho emociones básicas. Recordemos que la correlación es un valor entre -1 y 1. Se puede corroborar que la clasificación solo presenta una correlación significativa y negativa con la Confianza.
Figura 3
Correlación entre los grupos Depresivo y No Depresivo -Clasificación- de acuerdo con cada emoción.
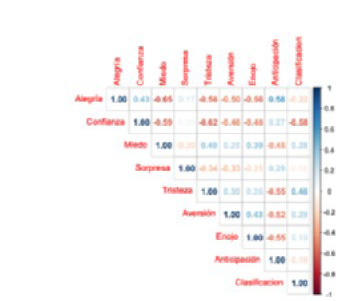
Nota: Elaboración propia.
Tenemos que los pesos de las ocho emociones básicas dadas por los especialistas a través del PJA están dados en la Tabla 2. Así pues, se puede calcular el IRD de cada persona mediante la ecuación (1). Se calculó el IRD para los 277 perfiles y se realizó una clasificación jerárquica. Se calculó el número óptimo de clases o conglomerados de acuerdo con diferentes métodos (Ward.D, Ward.D2, simple, completo, promedio, mediana y centroide, ver León (2019)) y considerando el IRD. En la Figura 4 se presentan los dendogramas de clasificación considerando el número de conglomerados óptimo de acuerdo con cada método.
Figura 4
Dendogramas utilizando varios métodos.
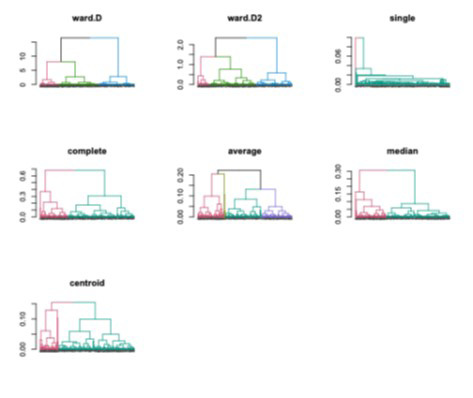
Nota: Elaboración propia.
Se eligió trabajar con el método Ward.D2, por ser un método muy utilizado en la literatura. El número de conglomerados óptimo que este método arrojó fue de 3. Así pues, se clasificaron los perfiles de acuerdo con su IRD en 3 conglomerados. En la Figura 5 se presenta el IRD de los perfiles de acuerdo con la clasificación obtenida por el Ward.D2. A los perfiles con menor IRD se les denominó Leve, seguido del conglomerado Moderado y por último el conglomerado Severo.
Figura 5
Clasificación de acuerdo con los grupos Depresivos y No Depresivos y a su IRD.
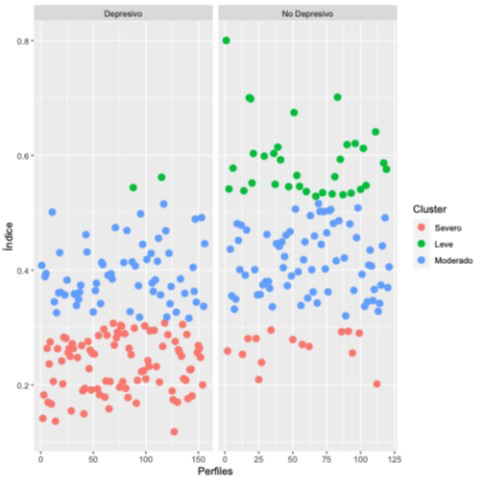
Nota: Elaboración propia.
El grupo Depresivo presenta 91 casos en el conglomerado Severo, 63 en el Moderado y solamente 2 en el Leve; mientras que el No Depresivo tiene 15 perfiles en el conglomerado Severo, 72 en el Moderado y 34 en el Leve.
Considerando el 80% de los perfiles como conjunto de entrenamiento (es decir 221 perfiles elegidos aleatoriamente) y el resto 20% como conjunto de prueba (56 perfiles) se realizó la predicción del grupo al que pertenecerían éstos últimos utilizando cinco clasificadores: Bayes, kknn, LDA, nnet y SVM, y distintos métodos de remuestreo. Dado que se tiene el registro real del grupo al que pertenecen los perfiles de prueba y su predicción se pudo calcular la precisión de cada clasificador, es decir, la proporción de perfiles bien clasificados, y para esto se utilizó la librería mlr3 del paquete estadístico R. Los resultados de la precisión se presentan en la Figura 6. Observamos que el SVM obtuvo la mejor precisión en 5 de los 6 métodos de remuestreo considerados. También se observa que LDA en general obtiene precisiones aceptables.
Figura 6
Precisión de los diferentes métodos de remuestreo utilizando diferentes clasificadores.
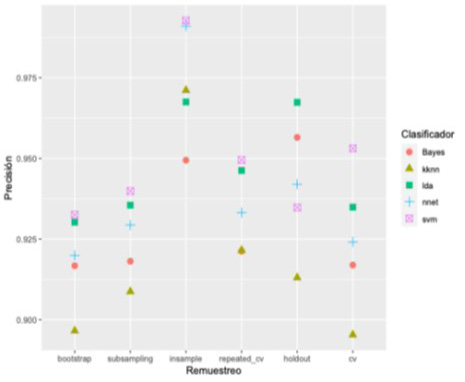
Nota: Elaboración propia.
Utilizando el SVM, en la Figura 7 se presentan las densidades entre los conglomerados Leve, Moderado y Severo y las ocho emociones básicas. Note que la densidad del conglomerado Severo está sesgada a la derecha en las emociones de tristeza, miedo, enojo y aversión. Por su parte, la densidad del conglomerado Leve se encuentra sesgada a la derecha en las emociones de alegría, anticipación y confianza. Mientras que la densidad del conglomerado Moderado siempre permanece entre las densidades de los otros dos grupos.
Figura 7
Densidades entre los grupos (Leve, Moderado y Severo) y las emociones básicas.
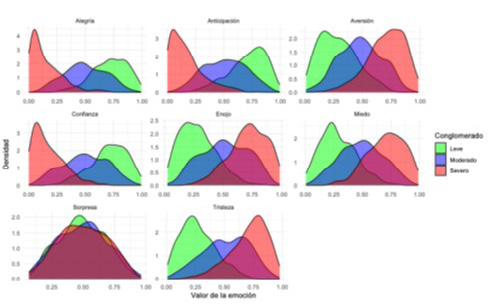
Nota: Elaboración propia.
3. Discusión
En el artículo Rodríguez et al. (2019) se realizó un análisis similar al presentado en este trabajo, pero considerando el suicidio, ellos encontraron que tristeza y enojo tenían los mayores pesos, seguidos de miedo y aversión. Un grupo final con pesos despreciables fueron las emociones de anticipación, sorpresa, confianza y por último alegría. En este trabajo también se pudieron diferenciar dos grupos (por su importancia), el primero conformado por: tristeza, enojo, miedo y aversión. El segundo está conformado por: anticipación, sorpresa, confianza y alegría. Note que ambos grupos coinciden tanto para la depresión como para el suicidio. La principal diferencia entre estos trabajos radica en el peso otorgado a la tristeza en depresión de aproximadamente 0.37 comparado con el de suicidio que resultó de aproximadamente 0.25.
Se ha encontrado que las personas con depresión moderada, comparadas con individuos sanos, muestran tener más signos de expresión en lenguaje figurado, respuestas más largas, predominancia de textos escritos en una cláusula en lugar de varias, un orden atípico en las palabras, mayor uso de pronombres personales y pronombres indefinidos, y verbos usados en tiempo pasado y continuo/imperfecto (Smirnova et al., 2018). Los autores también identificaron que los predictores más altos para discriminar grupos con depresión moderada y tristeza común a través de la expresión escrita fueron las variables de orden de palabras (típico/atípico), puntos suspensivos, coloquialismos, forma verbal (continuo/perfecto), cantidad de reflexivo/personal, y pronombres negativos e indefinidos.
Eichstaedt et al. (2018) encontraron un valor significativo de predictibilidad para un estatus de depresión futura hasta tres meses antes del primer registro clínico. Además, presentaron un modelo de evaluación no intrusiva de indicadores de depresión a través de redes sociales, que muestra ser una herramienta confiable y un complemento escalable para el monitoreo de emociones.
De Choudhury et al. (2013) fueron los pioneros en identificar usuarios depresivos en Twitter. Por su parte, Tsugawa et al. (2015) identificaron el nivel de depresión en usuarios de Twitter utilizando un modelo de máquinas de soporte vectorial. Mientras que Orabi et al. (2018) presentaron un modelo para detectar depresión aplicándolo a herramientas de aprendizaje profundo (deep learning en inglés). Los autores además desarrollaron modelos basados en redes neuronales artificiales como técnicas de clasificación con altos niveles de exactitud, al determinar si un usuario presentaba o no señales de depresión.
Jamil (2017) desarrolló una metodología para la detección de depresión en usuarios de Twitter, a nivel tuit. Con este análisis, los niveles de exactitud estuvieron sesgados por la desproporcionalidad que había entre los tuits con contenido depresivo y aquellos que no lo presentaban, por lo que optaron por un análisis a nivel usuario, considerando el porcentaje de tuits depresivos, mejorando así la clasificación de usuarios deprimidos. Estas clasificaciones se llevaron a cabo utilizando SVM.
Tal como se esperaba, la relación de género entre los grupos depresivos y no depresivos marcó una tendencia de mayoría para las mujeres en el caso de la recopilación de expresiones del grupo depresivo (Instituto Nacional de Estadística y Geografía, 2021).
De manera similar, los pesos de las principales emociones displacenteras asociadas con la anhedonia3 son notablemente altos, como se evidencia en las gráficas del análisis de sentimientos. Esto sugiere una distinción entre el discurso no depresivo y el de usuarios cuyos comportamientos podrían indicar un riesgo de trastorno depresivo mayor (García, 2021). Sin embargo, es importante considerar que estas expresiones emocionales pueden estar influenciadas por la dinámica de las redes sociales, que a menudo promueve la espectacularización y la búsqueda de interacción.
Es posible que la alegría y la confianza hayan tenido lugar a puntuaciones más altas que el enojo, por ejemplo, debido a la naturaleza de la muestra tomada. Pues los indicadores estudiados en esta investigación son puntuales y no recogen información longitudinal que indique el desarrollo de un trastorno que pueda observarse de forma clara y prolongada en el tiempo de vida de una persona, obteniendo así resultados de la variación en el estado de ánimo de las personas en la red social.
Bajo esto, cabe la lógica de haber seleccionado tuits que representen el estado de ánimo de personas que pasan por episodios depresivos y no necesariamente que vivan el trastorno depresivo mayor.
4. Conclusiones
La pandemia causada por el virus SARS-CoV-2 tomó un giro inesperado en México al comienzo del año 2022 debido a la variante Ómicron. Con las medidas de distanciamiento social implementadas para evitar la propagación de este virus, se presentaron problemáticas de salud mental, como lo son la ansiedad y depresión, trayendo como consecuencia una necesidad de atención a pacientes a distancia. Así pues, se requirieron herramientas de apoyo para identificar individuos en riesgo de padecer dichos trastornos. El distanciamiento implicó por su parte un aumento del uso de las redes sociales de los individuos, las cuales se convirtieron en plataformas para almacenar datos de diferente tipo, en particular, tipo texto. En esta investigación hemos abordado el análisis de texto para detectar usuarios de Twitter que presentaron el trastorno de depresión mayor a inicios de este año, en particular realizando un análisis de sentimientos.
Dos aportes importantes de este artículo son los pesos que los expertos en salud mental les otorgaron a las ocho emociones básicas considerando perfiles con trastorno de depresión mayor a través del Proceso Jerárquico Analítico, siento la tristeza quien obtuvo el mayor peso, seguida del enojo, la aversión, el miedo, anticipación, sorpresa, alegría y confianza. El otro gran aporte es la clasificación de usuarios a partir de la propuesta de un nuevo índice: el Índice de Riesgo a la Depresión, capaz de encontrar información relevante de los usuarios y cuya estructura matemática es muy simple, pues solamente suma los cuadrados de las diferencias entre el peso dado por el especialista y el peso obtenido por cada perfil a través del análisis de sentimientos, obteniéndose así un índice cuyos valores están entre 0 y 1; si la suma es muy pequeña (es decir, IRD cercano a 0) indica que el perfil tiene altos riesgos de padecer el trastorno de depresión mayor.
En la literatura existen distintas técnicas de clasificación como Máquinas de Soporte Vectorial, Bayes, Análisis Discriminante Lineal, Redes Neuronales, los cuales nos ayudaron a clasificar a los usuarios en grupos de grados de depresión: Leve, Moderado y Severo. El clasificador SVM resultó tener mejores precisiones de clasificación.
Cabe señalar que las herramientas aquí presentadas no tienen como objetivo sustituir a los especialistas en salud mental, sino que buscan servir como ayuda a éstos para identificar a individuos con alto riesgo de tener depresión.
Referencias
Acosta-Hernández, M. E., Mancilla-Percino, T., Correa-Basurto, J., Saavedra-Vélez, M., Ramos-Morales, F. R., Cruz Sánchez, J. S., & Duran Niconoff, S. (2011). Depresión en la infancia y adolescencia: enfermedad de nuestro tiempo. Archivos de neurociencias, 16(1), 20-25. https://www.medigraphic.com/pdfs/arcneu/ane-2011/ane111e.pdf
American Psychiatric Association. (2013). Diagnostic and Statistical Manual of Mental Disorders (5th ed.; DSM-5). https://www.hakjisa.co.kr/common_file/bbs_DSM-5_Update_October2018_NewMaster.pdf
Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
De Choudhury, M., Gamon, M., Counts, S., & Horvitz, E. (2013, June). Predicting depression via social media. In Seventh international AAAI conference on weblogs and social media. https://doi.org/10.1609/icwsm.v7i1.14432
Degenhard, J. (2021). Forecast of the number of Twitter users in Mexico from 2017 to 2025. Statista. https://www. statista.com/forecasts/1144192/twitter-users-in-mexico
Eichstaedt, J. C., Smith, R. J., Merchant, R. M., Ungar, L. H., Crutchley, P., Preotiuc-Pietro, D. & Schwartz, H. A. (2018). Facebook language predicts depression in medical records. Proceedings of the National Academy of Sciences, 115(44), 11203-11208. https://doi.org/10.1073/pnas.1802331115
Gareth, J., Daniela, W., Trevor, H., & Robert, T. (2013). An introduction to statistical learning: with applications in R (2.a ed.). Springer. https://hastie.su.domains/ISLR2/ISLRv2_website.pdf
García, M. P. (2021). La anhedonia en la depresion [Doctoral dissertation], Universidad de Alcalá.
Huerta-Velasco, D. A., & Calvo, H. (2021). Using lexical resources for detecting offensiveness in Mexican Spanish tweets. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2021), CEUR Workshop Proceedings. CEUR-WS. org. http://ceur-ws.org/Vol-2943/meoffendes_paper2.pdf
Instituto Nacional de Estadística y Geografía. (2021). Presenta Inegi resultados de la primera Encuesta Nacional De Bienestar Autorreportado (Enbiare) 2021. Comunicado De Prensa Núm.. 772/21, 15–16. https://www.inegi.org.mx/programas/ enbiare/2021/
Jamil, Z. (2017). Monitoring tweets for depression to detect at-risk users [Doctoral dissertation]. Université d’Ottawa/University of Ottawa. http://dx.doi.org/10.20381/ruor-20310
León Martinez, J. (2019). Identificación de depresión mediante el análisis de sentimientos [Bachelor’s tesis]. Universidad de Extremadura. http://hdl.handle.net/10662/9538
Marrocchi, F., Rapetti, C., Maguitman, A. G., & Estévez, E. C. (2019). Minería de emociones y análisis visual aplicado a la red social Twitter. In XXV Congreso Argentino de Ciencias de la Computación (CACIC) (Universidad Nacional de Rio Cuarto, Córdoba, 14 al 18 de octubre de 2019). http://sedici.unlp.edu.ar/handle/10915/91386
Martínez, C. (2020). En México, 39% de los cibernautas utilizan Twitter. El Universal. https://www.eluniversal.com.mx/cartera/en-mexico-39-de-los-cibernautas-utilizan-twitter
Martins, R., Almeida, J. J., Henriques, P. R., & Novais, P. (2021, February). Identifying Depression Clues using Emotions and AI. In ICAART (2) (pp. 1137-1143). https://doi.org/10.5220/0010332811371143
Masse Fátima. (2022). Salud Mental Para Los Más Jóvenes. IMCO. https://imco.org.mx/salud-mental-para-los-mas-jovenes/
Mori, J. L. C. (2013). Características de la depresión en la adolescencia. Revista Digital EOS Perú, 1(1), 59-66. http://www.revistaeos.net.pe/index.php/revistadigitaleos/article/view/66
Nicolini, H. (2020). Depresión y ansiedad en los tiempos de la pandemia de COVID-19. Cirugía y cirujanos, 88(5), 542-547. https://doi.org/10.24875/ciru.m20000067
Orabi, A. H., Buddhitha, P., Orabi, M. H., & Inkpen, D. (2018, June). Deep learning for depression detection of twitter users. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic (pp. 88-97). https://aclanthology.org/W18-0609
Organización Mundial de la Salud. (2021) Depresión. https://www.who.int/es/news-room/fact-sheets/detail/ depression
Plutchik, R. (1980). A general psychoevolutionary theory of emotion. In Theories of emotion (pp. 3-33). Academic press. https://doi.org/10.1016/B978-0-12-558701-3.50007-7
Reguant-Alvarez, M., & Torrado-Fonseca, M. (2016), “El método Delphi”, Revista d’Innovació i Recerca en Educació, 9(1), Barcelona, Universitat de Barcelona, pp. 87-102. https://doi.org/10.1344/reire2016.9.1916
Rodríguez-Esparza, L. J., Barraza-Barraza, D., Salazar-Ibarra, J., & Vargas-Pasaye, R. G. (2021). Metodología de Análisis de Emociones para Identificar Riesgo de Cometer Suicidio Generado por el COVID-19. Revista Lasallista de Investigación, 18(2), 105-124. https://dialnet.unirioja.es/servlet/articulo?codigo=8843575
Rodríguez-Esparza, L. J., Barraza-Barraza, D., Salazar-Ibarra, J., & Vargas-Pasaye, R. (2019). Index of suicide risk in Mexico using Twitter. Journal of Social Researches, 5(15), 1-13. https://www.ecorfan.org/republicofnicaragua/researchjournal/investigacionessociales/journal/vol5num15/Journal_of_Social_Researches_V5_N15_1.pdf
Saaty, T. L. (1980). The analytic hierarchy process. McGraw hill international.
Saaty, T. (2001). The Analytic Network Process. In: Decision Making with the Analytic Network Process. Pittsburgh University Press;1- 26.
Saaty, T. L. (2008). Decision making with the analytic hierarchy process. International journal of services sciences, 1(1), 83-98.
Saloni D., Ritchie, H., & Roser, M. (2021). Mental Health. Our World in Data. https://ourworldindata.org/mental-health
Santomuro, D. F., Herrera, A. M. M., Shadid, J., Zheng, P., Ashbaugh, C., Pigott, D. M., ... & Ferrari, A. J. (2021). Global prevalence and burden of depressive and anxiety disorders in 204 countries and territories in 2020 due to the COVID-19 pandemic. The Lancet, 398(10312), 1700-1712. https://doi.org/10.1016/S0140-6736(21)021437
Smirnova, D., Cumming, P., Sloeva, E., Kuvshinova, N., Romanov, D., & Nosachev, G. (2018). Language patterns discriminate mild depression from normal sadness and euthymic state. Frontiers in psychiatry, 9, 105. https://doi.org/10.3389/ fpsyt.2018.00105
Tsugawa, S., Kikuchi, Y., Kishino, F., Nakajima, K., Itoh, Y., & Ohsaki, H. (2015, April). Recognizing depression from twitter activity. In Proceedings of the 33rd annual ACM conference on human factors in computing systems (pp. 3187-3196). https://doi.org/10.1145/2702123.2702280
WHO. (2021). Suicide. Who.int; World Health Organization: WHO. https://www.who.int/news-room/fact-sheets/ detail/suicide
WordStream. (2022). 40 Twitter Statistics Marketers Need to Know in 2022. https://www.wordstream.com/blog/ws/2020/ 04/14/twitter-statistics#:~:text=There%20are%20186%20million%20daily,million%20tweets%20sent%20per%20day
Yomaira Pabon, A. (2021). Intentos de suicidio y trastornos mentales. Revista Habanera de Ciencias Médicas, 20(4), 1–9. http://www.revhabanera.sld.cu/index.php/rhab/article/view/3967
1 Se hizo un muestreo a conveniencia con sujetos que cumplieran con los siguientes requisitos: Practicar psicoterapia en México y contar con cédula profesional para ejercerla.
2 Al respecto, este método no está diseñado para obtener resultados estadísticamente significativos, sino como una técnica que se adapta a la exploración de elementos que suponen una mezcla de evidencia científica y valores sociales. El tamaño sugerido para este tipo de técnica es de 6 a 30 sujetos (Reguant-Alvarez y Torrado-Fonseca, 2016).
3 Anhedonia se refiere a la incapacidad de experimentar placer en actividades que normalmente serían placenteras, como comer, socializar o disfrutar de pasatiempos. Este síntoma es común en trastornos como la depresión y puede llevar a una disminución significativa en la calidad de vida de quienes lo padecen.