Fumiyoshi Watanabe1, Michelle Robles1 y José A. García1,2 1 Keck Graduate Institute of Applied Life Sciences,
2 Laboratorio de Biología Teórica,
Dirección de Posgrado e Investigación, Universidad La Salle E-mail: jgarcia@keck.com
Recibido: Febrero 22, 2007. Aceptado: Julio 12, 2007
RESUMEN
Existen ciertas evidencias experimentales que sugieren un mundo primitivo en el que la molécula de ácido ribonucleico (RNA) era la molécula responsable de codificar la información genética y de catalizar un número limitado de reacciones. En este "mundo de RNA" pudo darse el origen del código genético actual. En este manuscrito se presenta una breve discusión sobre las principales teorías que se han propuesto sobre el origen del código genético.
Palabras clave: código genético, mundo de RNA.
ABSTRACT
There are several experimental evidences suggesting a primeval world where ribonucleic acid (RNA) was responsible of both code for genetic information, and of catalyze a limited number of reactions. Within this “RNA world” the origin of the current genetic code could happen. In this paper, a brief discussion on the main theories about the origin of the genetic code is discussed.
Key words: genetic code, RNA world.
INTRODUCCIÓN
A mediados del siglo XX se conoció la estructura del ácido desoxirribonucleico (DNA, por sus siglas en inglés) así como la manera en que la información genética era transmitida a las siguientes generaciones. Posteriormente, uno de los problemas que motivaron a la comunidad científica fue el dilucidar cómo se relacionaba la información genética contenida en el DNA con la secuencia de proteínas, necesarias para llevar a cabo los procesos celulares.
Era conocido que el alfabeto genético consistía de sólo cuatro nucleótidos, mientras que el alfabeto de proteínas consistía de veinte aminoácidos. Varios modelos teóricos fueron propuestos para establecer el llamado código genético que permitiría a las células traducir la información genética en proteínas. [1,2,3] A finales de la década de los años 50 ya existía evidencia experimental sobre la posible participación del ácido ribonucleico mensajero (mRNA) en el proceso de traducción. Francis Crick propuso la hipótesis de la "molécula adaptadora", en la que se consideraba que los aminoácidos interactuaban con el mRNA mediante un adaptador. Dado que para esos tiempos se consideraba que el código no podría contener traslapes [2], Crick sugirió́ un código libre de comas, en el cual se tendrían que descartar todos los tripletes que se prestaran a traslapes (e.g. AAA), con lo que restarían, precisamente, 20 posibles combinaciones, correspondientes a las moléculas adaptadoras con significado [3]. Es decir, un código libre de comas se construye de tal manera que cuando dos codones con significado (con traducción) se encuentran juntos, entonces los tripletes obtenidos por el traslape entre ellos, se descartan y se consideran sin significado.
En 1961, Marshall Nirenberg y Heinrich Matthaei publicaron sus estudios en los que utilizaron un sistema libre de células donde mRNA artificial puede usarse para la síntesis de proteínas [4]. El primer mRNA utilizado fue poli-U, obteniéndose un polipéptido de poli-fenilalanina. Hay que hacer notar, que el triplete UUU se consideraba sin sentido en los códigos libres de comas. [3] En los años posteriores, se siguieron asignando codones, hasta que el código genético quedo totalmente establecido para 1965. [5]
Una vez descifrado el código genético, se desecharon todos los modelos teóricos que previamente se habían formulado. Sin embargo, años más tarde, Crick propuso que probablemente los códigos libres de comas fueran antecedentes de uno primitivo, que posteriormente diera origen al código actual [6]. Estas especulaciones llevaron a formular diferentes escenarios, que al ser enriquecidos con cierta evidencia experimental [7], llevaron a Gilbert a proponer al mundo del RNA, como un evento importante en el origen de la vida [8]. En este manuscrito se presenta una breve revisión sobre las principales teorías acerca del origen del código genético, bajo el contexto del mundo del RNA.
EL MUNDO DEL RNA
La composición molecular del código genético primitivo era ciertamente confuso, hasta que se descubrió la actividad enzimática en las moléculas de RNA de Escherichia coli, en la cual la ribonucleasa-P cortaba enlaces fosfodiéster durante la maduración de la molécula del RNA de transferencia (tRNA). [9-11]
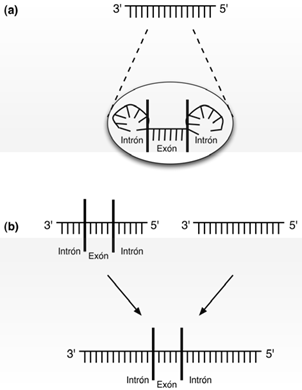
Este descubrimiento, en conjunción con el establecimiento de que el RNA ribosomal (rRNA) contenía exones de auto-procesamiento en la Tetrahymena [7,12,13], dieron inicio a la idea del mundo del RNA, en el que todo el conjunto de actividades primitivas de almacenamiento y catalíticas eran llevadas a cabo por cadenas de ribonucleótidos. Tal idea proponía que moléculas de RNA desempeñaban las actividades catalíticas necesarias para ensamblarse ellos mismos a partir de la sopa de nucleótidos. Aún más, se propone que las cadenas de RNA tenían capacidad de auto-procesamiento, es decir, los intrones se podían expulsar o introducir en una cadena de RNA, por sí mismos, sin ayuda de enzimas proteínicas como ocurre en la actualidad. Dicho proceso de auto- procesamiento podría generar que si dos intrones separados entre sí por un exón, se auto-liberaban de la cadena de RNA simultáneamente, se llevarían consigo al exón intermedio, el cual por medio de una auto-introducción en otra cadena no relacionada de RNA, generaría una mezcla de información genética primitiva, equivalente a procesos actuales como la recombinación, habilidad para producir nuevas combinaciones de genes, o mutaciones [8] (véase fig. 1).
Así, se propone que la evolución de dicho mundo al actual fue en etapas evolutivas, partiendo del mundo del RNA, en el que las moléculas de RNA fueron evolucionando en patrones de auto-replicación utilizando la recombinación y la mutación. Por medio de la utilización de RNA como cofactores desarrollaron entonces un rango completo de actividades enzimáticas. En la etapa posterior, el RNA comenzó a sintetizar proteínas, las cuales desempeñaban las mismas actividades catalíticas del RNA de manera más efectiva y rápida; siendo la última de las etapas la introducción de la doble hélice de DNA, que sirve actualmente como material de almacenaje de información genética.
(a) Cadena original de RNA con secuencia de procesamiento. (b) Introducción de la cadena original en otra secuencia no relacionada, dando origen a una cadena
híbrida.
Contradicciones sobre las bases originales del código genético primitivo
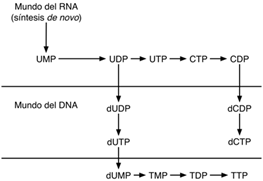
Como se ha venido mencionando, la idea de que el código primitivo fue un código de RNA y no de DNA, como es en la actualidad, se puede observar por la relación biosintética de ribonucleótidos y desoxirribonucleótidos, ya que éstos últimos son sintetizados después de los ribonucleótidos (véase fig. 2).
Según Jiménez-Sánchez [14], dicho código de RNA estaba formado por únicamente dos nucleótidos como son la A y el U, ya que de acuerdo a la vía biosintética de los nucleótidos, A y U preceden a la biosíntesis de los nucleótidos G y C, asimismo, el análisis del código genético contemporáneo, muestra que la mayor cantidad de información genética recae en las dos primeras letras de los tripletes. De igual forma, se ha visto que los cuatro nucleótidos contienen información diferente (véase tabla 1).
Organización de acuerdo con el número de aminoácidos codificados y/o señales de término por número de dobletes considerados.
Tercer nucleótido |
Significado/ Doblete |
|||||
Nucleótidos Primitivos |
Doblete |
G |
A |
U |
C |
|
AA |
Lys |
Asn |
2 |
|||
AU |
Met |
Ile |
||||
UA |
--- |
Tyr |
||||
UU |
Leu |
Phe |
||||
Nucleótidos Primitivos + Nucleótidos Recientes |
AG |
Arg |
Ser |
1.6 |
||
AC |
Thr |
|||||
UG |
Trp |
--- |
Cys |
|||
UC |
Ser |
|||||
GA |
Glu |
Asp |
||||
GU |
Val |
|||||
CA |
Gln |
His |
||||
CU |
Leu |
|||||
Nucleótidos Recientes |
GG |
Gly |
1 |
|||
GC |
Ala |
|||||
CG |
Arg |
|||||
CC |
Pro |
|||||
Podemos observar que cuando las letras A y/o U se encuentran en la primera y segunda posición, 4 diferentes dobletes dan información para ocho diferentes significados (siete aminoácidos y un codón de paro), siendo la relación de significado/doblete de 2.
Cuando los dobletes se encuentran conformados por un nucleótido viejo (A o U) y un nucleótido nuevo (G o C), se crean ocho dobletes, codificando para 13 significados (12 aminoácidos y un codón de paro), dando una relación de significado/doblete de 1.6. Finalmente cuando los dobletes se encuentran conformados por nucleótidos recientes se forman 4 dobletes, codificando para 4 aminoácidos, siendo la relación significado/doblete de 1.
De acuerdo con la comparación de las relaciones significado/doblete para los tres tipos de dobletes formados (nucleótidos primitivos, nucleótidos mezclados y nucleótidos recientes), podemos observar que los dobletes formados únicamente por nucleótidos primitivos, codifican para una mayor cantidad de información, en relación con la cantidad de dobletes que éstos generan. Los segundos en cuanto a la cantidad de información que codifican, son aquellos dobletes que contienen por lo menos un nucleótido primitivo en la primera o segunda posición; y los que contienen la menor cantidad de información son aquellos dobletes formados únicamente por nucleótidos recientes. [14] Esto sugiere que el mundo del RNA comenzó con polinucleótidos formados por las bases A y U, dada la propiedad de dichos nucleótidos para contener una gran cantidad de información.
Otras de las hipótesis que soportan la idea del autor es que si el código original estaba formado por A y U, dicho código contendría tanto el codón de iniciación (AUG) así como el codón de paro (UAA).
El siguiente paso evolutivo introdujo dos nuevos nucleótidos (G y C) de forma gradual, que causaron un incremento de ocho veces en el contenido informativo (de 8 a 64 codones), sin cambios en la maquinaria primitiva de traducción ni en el tamaño de los genes. Dicho paso evolutivo es supuesto por la teoría de que ambas bases otorgarían una mayor estabilidad fisicoquímica al código genético, sin generar grandes cambios entre las propiedades de los aminoácidos, ya que dichos nucleótidos (G y C) tienen mayor propensión a formar puentes de hidrógeno (A y U forman 2 puentes de hidrógeno mientras G y C pueden formar 3 puentes de hidrógeno).
Por otro lado, Hyman Hartman [15] propone la idea de que el origen del código genético está relacionado tanto a la evolución de los tRNAs como al origen de la membrana. En cuanto a la idea del origen del código genético a partir de la evolución del tRNA, propone que según el modelo de expansión de vocabulario propuesto en 1975, el código primitivo era un código de G y C exclusivamente, cuyos aminoácidos codificados eran: glicina (GG), prolina (CC), alanina (GC) y arginina (CG), posteriormente el código evolucionó al adicionarse la A para formar un código de GCA, el cual codificaba para nuevos aminoácidos como: ácido glutámico, ácido aspártico, glutamina, asparagina, lisina, histidina, treonina y serina. Finalmente se adicionó la U al código para formar el código de cuatro bases (GCAU), codificando los últimos aminoácidos: valina, leucina, isoleucina, metionina, fenilalanina, tirosina, triptófano y cisteína. Esto es, la evolución del código genético fue a partir de un código de GC que codificaba para polipéptidos estructurales, dichos polipéptidos evolucionaron en enzimas complejas conforme se fueron incorporando la A y la U al código. Esta propuesta es apoyada por artículos sobre la evolución del tRNA, uno de los cuales establece la existencia de remanentes del código primitivo en los bucles del tRNA actual [15].
Por otro lado en cuanto a la idea del origen del código genético a partir del origen de la membrana se establece que, considerando que las membranas deben poseer dominios hidrofílicos e hidrofóbicos, [16] de acuerdo con el código dinucleótido de GC, el polipéptido con dominio hidrofílico-hidrofóbico, más simplemente codificable por dicho código, eran los polipéptidos de alanina-arginina los que, se cree, pudieron funcionar como aminoacil-tRNA sintetasas, de acuerdo con el descubrimiento reciente de las propiedades catalíticas que poseen dichos tipos de polipéptidos. [17]
Otro de los experimentos propone que la membrana en realidad funcionaba para cubrir superficies, no para encapsular, si éste era el caso para la membrana primitiva, entonces un código aún más simple podría generar un oligómero de glicina o prolina capaz de desempeñar dicha función. Esto lleva a proponer que el código inicial fue únicamente de G o C, al cual, posteriormente, se le incorporó el nucleótido C o G para generar un nuevo código de GC. [18] El soporte experimental es que la reacción de montmorillonita-cuprosa (o ión zinc) en presencia de dímeros de glicina, incorpora el nucleótido C o G, a una cadena mononucleótida de G o C, respectivamente. [19,20]
Es ampliamente aceptado que hubo una era en el origen de la vida en la que el RNA tenía el papel tanto de material genético como de agente principal de la actividad catalítica, [21-35] dicha era es conocida como “El mundo del RNA”. [8]
Las evidencias a favor de esta etapa se pueden subdividir en 2 categorías: evidencia de naturaleza histórica-evolutiva y evidencia obtenida a partir de estudios para conocer el rango de actividad catalítica del RNA [35], la primera de las evidencias es sustentada por todas aquellas observaciones y sugerencias que pueden implicar un papel aún más fundamental del RNA en ciertos momentos evolutivos, tales como la existencia de coenzimas de bases nitrogenadas cíclicas, involucradas en la catálisis moderna en complejos enzima-coenzima, que pueden ser vestigios de enzimas originalmente formadas en el mundo del RNA. [23,36]
En cuanto a la segunda evidencia, existen experimentos con ribozimas artificiales, construidas usando experimentos de evolución directa, las que pueden catalizar numerosas reacciones. [37] Aunque estos experimentos se basan en la posible participación del componente 23S del rRNA en la actividad peptidil-transferasa, no se demuestra la actividad catalítica del rRNA per se. [38] Por ello, este reporte tiene una escasa implicación en el hecho de que existiera un mundo de RNA. [38]
De acuerdo con lo anterior y debido a evidencias como el hecho de que las proteínas actuales utilizan coenzimas nucleotídicas como cofactores, y no los RNAs a los aminoácidos como cofactores, se propone la existencia de un mundo mixto de RNA y péptidos, y no de un mundo de sólo RNA como sostienen otros autores. [38]
White [23] propone que las enzimas ancestrales eran moléculas de RNA y que las coenzimas son los vestigios de este sistema. Sin embargo, estudios han demostrado que a pesar de que algunas coenzimas pueden tener una actividad catalítica muy reducida (aún sin la presencia de la enzima), son necesarias las enzimas para que aquellas tengan una mayor actividad catalítica. [23,39-45] Aún más, se han hecho estudios que indican que otras coenzimas son incapaces de presentar tal actividad sin la presencia de la subunidad proteínica [45,46], por lo tanto, Di Giulio [35], propone que las coenzimas nucleotídicas y sus derivados utilizaban aminoácidos desde una era muy temprana.
White [47] propone un modelo para la evolución de los complejos enzima-coenzima. Dicho modelo comienza con una molécula de RNA, que posee un sitio activo (semejante a una coenzima) covalentemente unido en el interior de ésta. Las subsecuentes dos etapas son ribonucleoproteínicas, siendo la tercera etapa, la que muestra la expansión del componente proteínico y a su vez la reducción del componente polinucleótido para, finalmente, en la cuarta etapa llegar a la situación actual en la que se observa una enzima proteínica con una coenzima nucleotídica o derivada de ésta (véase fig. 3).
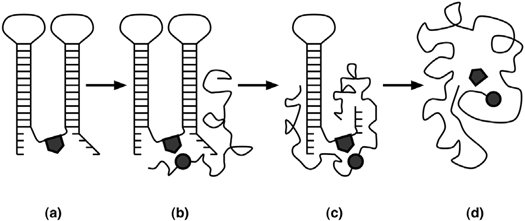
(a) Polinucleótido con sitio activo. (b) Formación del complejo ribonucleótido- proteína. (c) Expansión del componente proteínico y reducción del componente ribonucleotídico. (d) Enzima con una coenzima nucleotídica o derivada de ésta.
Por otro lado, Di Giulio [35], propone un modelo que comienza a partir de una coenzima nucleotídica con uno o más aminoácidos unidos a él, dichas coenzimas pueden generar tanto la síntesis de péptidos como la del RNA, por lo cual jugaban un papel catalítico muy importante en el metabolismo primitivo. La segunda y tercera etapa muestran a dicha coenzima unida a partir de uno de los extremos a una molécula de RNA desencadenando así la doble síntesis (péptido y RNA). Finalmente, en la cuarta etapa se observa la situación actual con la coenzima interactuando con el sitio activo de la enzima proteínica (véase fig. 4).
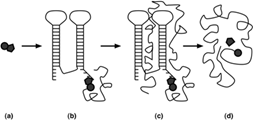
(a) Nucleótido con uno o más residuos de aminoácidos unidos covalentemente.
(b) Asociación con una molécula de RNA. (c) Síntesis de RNA y proteína.
(d) Coenzima interactuando con el sitio activo de la enzima.
A diferencia del modelo de White [47], en el modelo de Di Giulio [35] la coenzima nucleotídica está posicionada al final de la molécula del RNA y no dentro de ésta, lo que se soporta con evidencia experimental donde la estructura de algunas coenzimas nucleotídicas (Coenzima A, FAD, NAD, cobalamida y F420) sugieren que la coenzima debió de haberse situado en el extremo 5’ de los RNAs. Otra de las diferencias es que en el modelo de White [47] no se explica el surgimiento de la peptidil-tRNA, que es una estructura fundamental para el origen de la síntesis de proteínas, mientras que Di Giulio, sugiere la presencia de las peptidil-tRNAs desde una fase temprana del mundo ribonucleopéptido.
La teoría de la coevolución propuesta inicialmente por Wong [48], propone que existió una relación biosintética entre los aminoácidos y la estructura del código genético. Es decir, esta teoría propone la existencia de escasos aminoácidos codificados en la temprana etapa del desarrollo del código genético; dichos aminoácidos precursores, pronto generarían nuevos aminoácidos productos, los cuales acaparaban los codones de sus precursores por medio de moléculas semejantes a tRNAs. [48,49]
Como apoyo a la teoría evolutiva, algunos autores han aportado descubrimientos importantes como Nirenberg [50] quien reconoció la existencia de contigüidad entre codones que codifican para aminoácidos sintetizados por un precursor común y Dillon [51], quien reconoció que la distribución de codones-aminoácidos pudo ser guiado por relaciones biosintéticas entre los últimos. Actualmente esta teoría se ve reforzada por evidencias de transformaciones de aminoácidos precursores en aminoácidos productos, como se observa, con la vía Met-tRNAfMet ® fMet-tRNAfMet que está presente en el dominio de las bacterias y en organelos celulares. [52]
Otro de los artículos que apoyan fuertemente a esta teoría es el estudio del nivel de optimización de las propiedades fisicoquímicas de los aminoácidos en el código genético por medio de la medición de las polaridades, masas moleculares y distancias entre los aminoácidos dispuestos en grupos biosintéticamente relacionados obteniéndose así la mínima distancia entre los aminoácidos. Esto llevó a proponer que el código genético no posee características que lo puedan clasificar como un mínimo local y mucho menos como un mínimo absoluto, al menos en el sentido matemático. Por lo que, el código genético podría estar aún en una etapa evolutiva, cuya evolución se ha visto disminuida. [53] Se puede pensar que fue una interacción aminoácido-anticodón, lo que llevó al código a su nivel de optimización actual. Esto parece favorecer la teoría de la coevolución del código genético, la cual predice que las propiedades fisicoquímicas de los aminoácidos deben estar ligadas a la organización del código genético. [54]
Propone que la sucesión de los codones de aminoácidos precursores a aminoácidos producto era llevada a cabo por moléculas similares al RNA, como los aminoacetil-tRNA sintetasas, los que se cree eran las moléculas encargadas de unir los aminoácidos a los tRNAs. Dichos aminoacetil-tRNA sintetasas que provienen filogenéticamente de un tronco común a las tRNA sintetasas [55,56], se encuentran subdivididas en dos grupos aparentemente no relacionados entre sí, cada uno de los cuales contiene un total de 10 aminoácidos diferentes entre los grupos. [57-59]
La división de los 20 aminoácidos entre las dos clases de aminoacetil-tRNA sintetasas quedaría de la siguiente forma:
• Clase I: valina, leucina, isoleucina, metionina, tirosina, triptofano, ácido glutámico, glutamina, arginina y cisteína.
• Clase II: histidina, fenilalanina, aparagina, ácido aspártico, alanina, glicina, prolina, treonina, serina y lisina.
Experimentalmente se ha comprobado que las aminoacetil-tRNA sintetasas de clase II son más primitivas que las de clase I, basándose en la teoría de que el código primitivo era predominantemente constituido por los nucleótidos G y C. Para esto, se midió la variable x que representa la abundancia relativa de los nucleótidos C y G sobre los nucleótidos A y U en los nucleótidos codificantes de los aminoácidos pertenecientes a ambas clases de aminoacetil-tRNA sintetasas, observándose que los aminoácidos pertenecientes a la clase II tenían un valor de x mayor que la de los aminoácidos de la clase I. [60]
Esta teoría sugiere una interacción estereoquímica entre codones o anticodones y aminoácidos, lo que pudo haber proporcionado una fuerte influencia espacial dentro de la evolución del código genético; es decir, que sólo los aminoácidos que tuvieran una conformación espacial complementaria o similar a la estructura codón-anticodón serían los candidatos para formar parte del código genético.
Algunos modelos que apoyan a esta teoría son:
Gamow [1], propuso una relación de "llave y cerradura" entre varios aminoácidos y los espacios de un rombo formado por cuatro nucleótidos en la cadena del DNA. Este modelo está dotado con la propiedad de ser capaz de codificar, como máximo, para 20 aminoácidos y corresponde al primer modelo teórico propuesto para un código genético.
Melcher [61] construyó modelos estableciendo una correlación estereoquímica entre aminoácidos y sus correspondientes anticodones. El aspecto principal de estos modelos fue, por un lado, la intercalación del aminoácido y, por el otro, el enlace entre el átomo de hidrógeno alifático del aminoácido, a través de enlaces de hidrógeno a los electrones π de las bases. Posteriormente, Balasubramanian [62] propuso modelos basados en oligorribonucleótidos de cinco residuos, teniendo un U en el extremo 5’, una purina en el extremo 3’ y cualquier combinación de las tres bases en el medio (UNNNR). Estos oligorribonucleótidos, que son considerados por el autor como un tRNA primitivo, han demostrado poseer una conformación capaz de interactuar con sus correspondientes aminoácidos.
De manera similar, Shimizu [63] propuso un modelo basado en complejos de 4 nucleótidos en los tRNAs, que están constituidos por las bases de los anticodones y la base discriminadora en la cuarta posición del extremo 3’. Estos complejos demostraron poseer una relación de llave-cerradura con el correspondiente aminoácido.
Finalmente, en apoyo a la teoría estereoquímica, Yarus [64-67] descubrió la existencia de una interacción estereoselectiva entre el sitio de la guanosina en el centro catalítico de un RNA y la arginina. Esto parece sugerir un origen esteroquímico para el código genético.
Es una variante de la teoría estereoquímica que propone que la fuerza detrás del origen de la estructura del código genético es la que tendía a reducir las distancias fisicoquímicas entre aminoácidos codificados por codones que difieren en una sola base. Entre los autores que apoyan a este modelo destacan Sonneborn, quien identificó la presión selectiva que tendía a reducir los efectos deletereos de las mutaciones como la fuerza detrás de la definición de la localización de aminoácidos en la tabla del código genético, [68] así como Woese et al., quienes propusieron que la fuerza detrás de la definición de la organización del código genético es la presión selectiva que tendió a reducir los errores de traducción de los mensajes genéticos primitivos. [69]
Las observaciones en la hidrofobicidad de los compuestos moleculares del sistema de codificación del código genético han sugerido una organización no aleatoria de ésta. [70- 77] Se ha medido la hidrofobicidad de los 4 nucleótidos y de los 20 aminoácidos codificados, dando como resultado un orden de hidrofobicidad ascendente de U, C, G, A, siendo U el más hidrofílico y A el más hidrofóbico. [71,73] Asimismo, se encontró la mayor correlación de hidrofobicidad entre el segundo nucleótido del codón y su correspondiente aminoácido y por ende, con su correspondiente anticodón, dando como resultado que el nucleótido más hidrofílico (U) tiene como anticodón al más hidrofóbico (A); esto sugiere que los codones que codifican para los aminoácidos más hidrofílicos tienen como segundo nucleótido a la A, y por el otro lado, los que codifican para los aminoácidos más hidrofóbicos tienen como segundo nucleótido a la U. [74,75]
En otras palabras, esta teoría propone que el código genético se debió de organizar de modo tal, que cada segundo nucleótido de los codones tuviese una relación hidrofóbica inversa a la de los aminoácidos codificados, así como a los segundos nucleótidos de sus anticodones respectivos. A manera de ejemplo, la lisina, que es un aminoácido muy hidrofílico, tiene como segundo nucleótido en su codón a la A que es un nucleótido muy hidrofóbico, y siendo que el anticodón es el triplete complementario del codón, éste tendría en su segunda posición a la U que es un nucleótido muy hidrofílico.
Volumen de los aminoácidos y su relación con la organización del código genético Utilizando predicciones de asociación de RNA dobles por medio de cambios en la energía libre [78-80], se encontró que los aminoácidos pequeños eran codificados por los codones más fuertes mientras que los aminoácidos más largos eran codificados por los codones más débiles, esto sugiere que dentro de la organización del código genético también se ven involucradas algunas propiedades físicas como son el volumen de los aminoácidos, aunque existen ciertas excepciones como: asparagina, arginina y triptofano. [81]
De acuerdo con los dos puntos precedentes, se establece la hipótesis de que únicamente los aminoácidos que satisfacen los requerimientos expresados por las dos correlaciones anteriores, deben de entrar a la tabla del código genético en la que los parámetros de hidrofobicidad y volumen determinan sus posiciones respectivas. [81]
Al hacer experimentos prebióticos para generar aminoácidos, se observó que hay una gran prevalencia de ocupación de purinas (A o G) denominadas por la letra R, en la primera posición de los codones formados; es decir, un 99.4% de los codones formados, tenían una R como nucléotido inicial, mientras que sólo un 0.6% presentaron una pirimidina, Y (C o U) en el primer nucléotido del codón. Considerando que los codones no mostraban una prevalencia ocupacional tan remarcada ni en la segunda ni en la tercera posición del codón, se puede establecer que los codones presentaban la forma RNN, siendo N cualquier tipo de nucleótido tanto pirimidina como purina. [81]
La forma RNN también puede verse en secuencias codificantes actuales. Estas observaciones parecen favorecer la hipótesis de que el código genético no es aleatorio, debido a que una asignación aleatoria de aminoácidos a codones no se espera que afecte el patrón general de codificación de secuencias.
La asignación de aminoácidos a los codones del código genético se cree que ocurrió en 2 diferentes etapas, es decir, la correlación de volumen y la de hidrofobicidad no ocurrieron en el mismo momento sino que son fenómenos de diferentes fases de la estructuración del código genético.
Se ha hipotetizado la existencia de una estructura de tRNA en forma de bucle (anticodón), que era estabilizado por un tronco de RNA de cierta longitud, dicha molécula se cree que era la estructura de RNA más simple, con propiedades de polimerización de aminoácidos. [82] Suponiendo que a dicha estructura se le uniera un aminoácido con cierto volumen, en el extremo 3’ del tronco estabilizador, el volumen total de la unión tRNA-aminoácido, no sería muy diferente del tRNA solo, lo cual indica que no se afectan las propiedades del tRNA, dependiendo del tipo de aminoácido (volumen) que se una al tRNA; sin embargo, lo que sí se ve afectado por el volumen del aminoácido, es la energía libre dependiente del tiempo, es decir, entre más pequeño es el aminoácido, éste permanece un tiempo más prolongado unido al tRNA, siendo que un aminoácido de mayor volumen permanece unido un tiempo menor. Esto nos indica que un aminoácido de volumen pequeño necesita mayor tiempo que un aminoácido de mayor volumen, en generar el enlace covalente para unirse a la cadena peptídica y generar la proteína, es decir, un aminoácido de mayor volumen tiene una mayor tasa de reactividad que un aminoácido de volumen pequeño. [81]
Experimentos realizados para comprobar la tasa de reactividad dependiente del volumen de la molécula, han demostrado que la reactividad de la molécula depende de la cadena variable de la misma. [83] De esta forma, al extrapolar estos resultados, a las estructuras de los aminoácidos, se puede decir que la tasa de reactividad de los aminoácidos depende de la longitud de la cadena asociada al carbono alfa, así la glicina que tiene un H como cadena variable, tendrá menor tasa de reactividad que la alanina que tiene un radical metilo. [81]
El parámetro de hidrofobicidad entra en juego para formar el enlace covalente entre el aminoácido y el extremo 3’ del tRNA. [81] El proceso anterior comienza con un tRNA que posee un tronco estabilizador de 6 pares de bases de longitud y 4 nucleótidos libres en el extremo 3’, mientras que por el extremo cerrado (bucle) correspondiente al anticodón del RNA, posee 3 nucléotidos libres, de los cuales, el segundo nucleótido tiene la mayor carga en la determinación de la hidrofobicidad de la molécula; así, cuando los aminoácidos libres son reconocidos por el extremo anticodón del tRNA, y ambos (aminoácido y segundo nucleótido anticodón) muestran tener una correspondencia de hidrofobicidad, la estructura general del tRNA pierde estabilidad termodinámica, generando que se disocie de manera que el extremo 3’ de la misma pueda alcanzar al aminoácido para generar así el enlace covalente entre ambos. Una vez unido el aminoácido al extremo 3’, la estructura completa regresa a su estado natural (bucle- tronco-aminoácido), ya que ésta tiene una mayor estabilidad termodinámica que la cadena disociada (véase fig. 5).
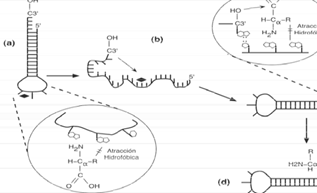
(a) Interacción hidrofóbica entre un aminoácido y una molécula de RNA.
(b) Desnaturalización de la cadena de RNA. (c) Ataque nucleofílico del hidroxilo terminal en la cadena del RNA al aminoácido. (d) Formación del enlace covalente.
Modelo de horquillas
Hans Kuhn y Jürg Waser [82] proponen una teoría sobre el origen y evolución del código genético, partiendo de la explicación del mecanismo de síntesis de proteínas primitivo. El modelo propuesto para dicha síntesis contenía una hebra abierta de RNA, que servía como molde para la unión de estructuras tipo horquilla, en cuyos extremos cerrados, poseían los nucleótidos complementarios a la hebra molde (anticodón) que se unían a dicha hebra. Por otro lado, en el extremo abierto (en sentido opuesto al cerrado), la horquilla, poseía un aminoácido; así, un alineamiento de dichas estructuras, a lo largo de toda la hebra molde, generaba un aparato completo de síntesis de proteínas, y dicha alineación al ser muy estrecha (no había casi espacios entre horquilla y horquilla), generaba una leve atracción entre los aminoácidos decodificados facilitando de esta manera la formación de cadenas oligoméricas de péptidos (véase fig. 6).
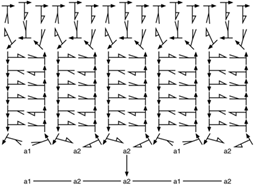
Posteriormente, al evolucionar la maquinaria de síntesis de proteínas, la hebra molde evolucionó hacia lo que hoy se conoce como el mRNA, mientras las estructuras tipo horquilla se transformaron en tRNA, y todo el sistema completo, es decir, cadena molde y estructura horquilla, se convirtió en el ribosoma. [82]
El origen de la maquinaría de síntesis propuesta, fue a partir de dos tipos de monómeros diferentes capaces de generar puentes de hidrógeno entre sí, con el objeto de alinearse lateralmente y crear una hebra (molde), posteriormente dicha hebra podría servir como molde para formar nuevas. Los monómeros propuestos por Kuhn y Waser para producirla fueron G y C, por su mayor capacidad de hacer puentes de hidrógeno. [82]
Una vez generada la hebra molde (código genético primitivo), ésta iba evolucionando debido a errores replicativos que se confirmaban a lo largo del tiempo, es decir, errores no letales, sino del tipo que proporcionaban una ventaja selectiva sobre las hebras molde sin error.
Así, el código genético primitivo propuesto, estaba constituido por los nucleótidos G y C, que codificaban únicamente para los aminoácidos glicina y alanina; las posteriores evoluciones del código, fueron gobernadas por varios factores, siendo uno de los más importantes la polaridad de los aminoácidos codificados, que se traducía por el tipo de nucleótido que daba origen a los aminoácidos, es decir, la polaridad dependía del nucleótido en la posición 2 del codón. Así, la A está asociada con una alta polaridad, la G con aminoácidos menos polares, la C con aminoácidos muy débilmente polares y por último, la U con aminoácidos no polares. [82]
Dentro de los patrones que garantizan una lectura sin traslapes (libre de comas), Crick propuso la secuencia de bases RRY, es decir, purina–purina–pirimidina para que fuera igual para todos los codones que especificaban un mensaje. [6] Sin embargo, debido al exceso de purinas en esta secuencia, su estructura es termodinámicamente más inestable. Gracias a esto, y a otros argumentos, Eigen y Schuster propusieron como alternativa de código primitivo, a uno que siguiera el patrón RNY, en donde N, representa cualquiera de los cuatro nucleótidos. [84]
Crick y cols. habían descartado este modelo porque presentaba como desventaja el que si la N fuese una pirimidina, el bucle del anticodón tenía que usar sus cinco nucleótidos centrales para formar pares de bases estables con el mensajero. [6] Eigen y Schuster, por su parte, argumentan que este código da lugar a ocho aminoácidos por lo que uno puede excluir ciertas combinaciones que no satisfacen los requisitos de estabilidad del complejo mensajero-peptidil-tRNA. [84] Aparte de esto, también mencionan que el código RNY presenta las siguientes ventajas: carece de comas, es simétrico con respecto a las cadenas positiva y negativa, puede desarrollar simetría interna en una sola cadena y por lo tanto, se permite la formación de estructuras secundarias.
La propuesta de Eigen y Schuster es consistente con resultados experimentales, donde se observa la abundancia de 8 aminoácidos bajo condiciones que asemejan a la Tierra primitiva [85], así como por su amplia presencia en genes actuales. [86-88] Asimismo, el patrón RNY ha sido considerado por Konecny y cols. como el código que pudo emplearse en el mundo del RNA. [89] Finalmente, análisis matemáticos sugieren que este código está más cercano al código genético estándar, cuando se compara con otros códigos alternativos. [90]
DISCUSIÓN
Una de las características mejor conservadas a lo largo de la evolución es el código genético. Aunque existen ligeras variaciones en algunos genomas mitocondriales, podemos considerarlo como universal. Esta universalidad, llevó a Francis Crick a proponer que el código genético actual es resultado de un "accidente congelado", es decir, que surgió por procesos estocásticos en determinado tiempo en la historia, y que una vez seleccionado quedó congelado en el sentido que no sufrió posteriores modificaciones. [91] Los cambios observados en genomas mitocondriales pueden explicarse, bajo esta perspectiva, en una menor presión selectiva por conservar la misma codificación.
La distribución de codones a aminoácidos sugiere que el origen del código genético dista de ser aleatorio. Como se mencionó en las secciones anteriores, existen evidencias experimentales que soportan ciertos aspectos de las teorías estereoquímica y fisicoquímica que contradicen la hipótesis del accidente congelado. Asimismo, análisis matemáticos muestran que el código genético actual supera en varios parámetros estadísticos a códigos alternativos con componentes de origen aleatorio. [90]
Todo esto nos lleva a pensar, que aunque pueden existir componentes aleatorios dentro del origen del código genético, también deben de haber jugado un papel importante otro tipo de componentes relacionados ya sea con las características fisicoquímicas de los aminoácidos codificados, así como con la evolución de otras macromoléculas.
En general, las teorías presentadas no son mutuamente exclusivas, aunque en lo particular tengan contradicciones importantes. Esto nos lleva a proponer la hipótesis de que eventos de diferente naturaleza jugaron algún tipo de papel en la conformación del código genético actual.
REFERENCIAS
[1] Gamow, G. (1954). "Possible relation between deoxyribonucleic acid and protein structures". Nature, 173, 318.
[2] Brenner, S. (1957). "On the impossibility of all overlapping triplet codes in information transfer from nucleic acid to proteins". Proc. Natl. Acad. Sci., EUA, 43, 687-694.
[3] Crick, FHC, Griffith, JS (1957). Orgel, LE. "Codes without commas". Proc. Natl. Acad. Sci., EUA, 43, 416–421.
[4] Nirenberg, MW, Matthaei, JH. (1969). "The dependence of cell-free protein synthesis in
E. coli upon naturally occurring or synthetic polyribonucleotides". Proc. Natl. Acad. Sci., EUA, 47, 1588–1602.
[5] Hayes, B. (1998). "The invention of the genetic code". American Scientist, 86, 8–14.
[6] Crick, FHC, Brenner, S, Klug, A, Pieczenik, G. (1976). "A speculation on the origin of protein synthesis". Origins of Life, 7. 389–397.
[7] Cech, TR, Zaug, AJ, Grabowski, PJ. (1981). "In vitro splicing of the ribosomal RNA precursor of Tetrahymena: involvement of a guanosine nucleotide in the excision of the intervening sequence". Cell, 27, 487–496.
[8] Gilbert, W. (1986). "The RNA world". Nature, 319, 618.
[9] Westheimer, FH. (1986). "Polyribonucleic acids as enzymes. Nature, 319, 534-535.
[10] Guerrier-Takada, C, Gardiner, K, Marsh, T, Pace, N, Altman, S. (1983). "The RNA moiety of ribonuclease P is the catalytic subnunit of the enzyme". Cell, 35, 849-857.
[11] Guerrier-Takada, C., Altman, S. (1984). "Catalytic activity of an RNA molecule prepared by transcription in vitro". Science, 223, 285-286.
[12] Kruger, K, Grabowski, PJ, Zaug, AJ, Sands, J, Gottschling, DE, Cech, TR. (1982). "Self-splicing RNA: autoexcision and autocatalyzation of the ribosomal RNA intervening sequence of Tetrahymena. Cell., 31, 147-167.
[13] Cech, TR. (1985). "Self-splicing RNA: implications for evolution". Int. Rev. Cytol. 93, 3-22.
[14] Jiménez-Sánchez, A. (1995). "On the origin and evolution of the genetic code". J. Mol. Evol. 41, 712-716.
[15] Hartman, H. (1983). "Speculation on the evolution of the genetic code III: the evolution of tRNA". Orig. Life, 14, 643-648.
[16] Orgel, L. (1987). "Evolution of the genetic apparatus: a review". Cold Spring Harb. Symp. Quant. Biol. 52, 9-16.
[17] Brack, A. (1993). "Liquid water and the origin of life". Orig. Life Evol. Biosph. 23, 3-10. [18] Hartman, H. (1995). "Speculations on the Origin of the Genetic Code". J. Mol. Evol.
40, 541-544.
[19] Saito, R, Terashima, R, Sakai, T, Tomita, K. (1974). "The cristal structure of cytosine- glycyl-glycine-copper(II) complex, a biologically important ternary coordination complex". Biochem. Biophys. Res. Commun. 61, 83-86.
[20] Szalda, DJ, Marzilli, LG, Kistenmacher TJ. (1975). "Dipeptide-metal-nucleoside complexes as models for enzyme-metal-nucleic acid ternary species. Synthesis and molecular structure of the cytidine complex of glycilglycinatocopper(II)". Biochem. Biophys. Res. Commun. 63, 601-605.
[21] Brachet, J. (1959). "Les acides nucléiques et l’origine des protéines". En: Oparin AI, Pasynskii AG, Braunshtein AE, Pavlovskaya TE (eds). The origin of life on the earth. Londres, Pergamon Press, 361-367.
[22] Woese, CR. (1967). The genetic code. New York, Harper and Row.
[23] White, HB III. (1976). "Coenzymes as fossils of an earlier metabolic state". J. Mol. Evol., 7, 101-104.
[24] Pace, NR, Marsh, TL. (1985). "RNA catalysis and the origin of life". Orig. Life, 16, 97- 116.
[25] Sharp, PA. (1985). "On the origin of RNA splicing and introns". Cell, 42, 397-400.
[26]. Alberts, BM. (1986). "The function of the hereditary materials: biological catalyses reflect the cell’s history". Am. Zool., 26, 781-796.
[27] Cech, TR. (1986). "A model for the RNA-catalyzed replication of RNA". Proc. Natl. Acad. Sci. USA, 83, 4360-4363.
[28] Lewin, R. (1986). "RNA catalysis gives fresh perspective on the origin of life".
Science, 231, 545-546.
[29] Weiner, AM, Maitzels, N. (1987). "3’ Terminal tRNA-like structures tag genomic RNA molecules for replication: implications for the origin or protein synthesis". Proc. Natl. Acad. Sci. USA, 84, 7383-7387.
[30] Benner, SA., Ellington, AD., Tauer, A. (1989). "Modern metabolism as a palimpsest of the RNA world". Proc. Natl. Acad. Sci USA, 86, 7054-7058.
[31] Gibson, TJ, Lamond, AI. (1990). "Metabolic complexity in the RNA world and implications for the origin of proteins synthesis". J. Mol. Evol., 30, 7-15.
[32] Joyce, GF. (1989). A evolution and the origins of life". Nature, 338, 217-224. [33] Joyce, GF. (1991). "The rise and fall of the RNA world". New Biol., 3, 399-407.
[34] James, KD, Ellington, AD. (1995). "The search for missing links between self- replicating nucleic acids and the RNA world". Orig. Life Evol. Biosph., 25, 515-530.
[35] Di Giulio, M. (1997). "On the RNA world: evidence in favor of an early ribonucleopeptide world". J. Mol. Evol., 45, 571-578.
[36] Orgel, LE. (1986). "RNA catalysis and the origins of life". J. theor. Biol., 123, 127-149.
[37] Lohse, PA, Szostak, JW. (1996). "Ribozyme-enzyme catalysed amino-acid transfer reactions". Nature, 381, 442-444.
[38] Di Giulio, M. (1997). "On the origin of the genetic code". J. theor. Biol., 187, 573-581.
[39] Metzler, DE, Ikawa, M, Snell, EE. (1954). "A general mechanism for vitamin B6- catalized reactions". J. Am. Chem. Soc., 76, 648-654.
[40] Mizuhara, S., Handler, P. (1954). "Mechanism of thiamine-catalized reactions". J. Am. Chem. Soc., 76, 571-573.
[41] Snell, EE. (1958). "Structure in relation to biological activities of vitamin B6". Vitam. Horm., 16, 77-125.
[42] Breslow, R. (1958). "On the mechanism of thiamine action". J. Am. Chem. Soc., 80, 3719-3725.
[43] Hajdu, J., Sigman, DA. (1977). "Model dehydrogenase reactions. Catalysis of dehydronicotinamide reduction by non-covalent interactions". Biochemistry, 16, 2841- 2846.
[44] Haas, W, Hemmerich, A. (1979). Flavin-dependent substrate photooxidation as a chemical model of the dehydrogenase action". Biochem. J., 181, 95-105.
[45] King, GAM. (1980). "Evolution of the coenzymes". Biosystems, 13, 23-45.
[46] Hoffmann-Ostenhof, O. (1959). "Der ursprung der enzyme". En: Oparin AI, Pasynskii AG, Braunshtein AE, Pavlovskaya TE (eds). The origin of life on the earth. Londres, Pergamon Press, 197-206.
[47] White, HB III. (1982). "Evolution of coenzymes and the origin of pyridine nucleotides". En: Pyridine nucleotide coenzymes. Everse, J. (ed), New York, Academic Press, 1-17.
[48] Wong, JT. (1975). "The co-evolution theory of the genetic code". Proc. Natl. Acad. Sci., EUA, 72, 1909-1912.
[49] Di Giulio, M, Medugno, M. (1999). "Physicochemical optimization of the genetic code origin as the number of codified amino acids increases". J. Mol. Evol., 49, 1-10.
[50]. Nirenberg, MW, Jones, OW, Leder, P, Clark, BFC, Lsy, WS, Pestka, S. (1966). "On the coding of the genetic information". Cold Spring Harbor Symp. Quant. Biol., 28, 549- 557.
[51] Dillon, LS. (1973). "The origins of the genetic code". Bot. Rev., 39, 301-345.
[52] Di Giulio, M. (2001). "The non-universality of the genetic code: the universal ancestor was a progenote". J. theor. Biol., 209, 345-349.
[53] Ardell, DH. (1998). "On error minimization in a sequential origin of the standard genetic code". J. Mol. Evol., 47, 1-13.
[54] Di Giulio, M., Medugno, M. (2000). "The robust statistical bases of the coevolution theory of genetic code origin". J. Mol. Evol., 50, 258-263.
[55] Holmquist, R, Jukes, TH, Pangburn, S. (1973). "Evolution of transfer RNA". J. Mol. Biol., 78, pp. 91-116.
[56] Eigen, M, Lindemann, BF, Tietze, M, Winkler-Ostwatisch, R, Dress, A, von Haeseler,
A. (1989). "How old is the genetic code? Statistical geometry of tRNA provides an answer.
Science, vol. 244, pp. 673-679.
[57] Eriani, J, Delarue, M, Poch, O, Gangloff, J, Moras, D. (1990). "Partition of tRNA synthetases into two classes based on mutually exclusive sets of sequence motifs". Nature, 347, 203-206.
[58] Cusack, S, Berthet-Colominas, C, Härtlein, M, Nassar, N, Leberman, R. (1990). "A second class of synthetase structure revealed by X-ray analysis of Escherichia coli seryl- tRNA synthetase at 2.5 A". Nature, 347, 249-255.
[59] Nagel, GM, Doolittle, RF. (1991). "Evolution and relatedness in two aminoacyl-tRNA synthetase families". Proc. Natl. Acad. Sci., EUA, 88, 8121-8125.
[60] Ferreira, R, Calvacanti, AR. (1997). "Vestiges of early molecular processes leading to the genetic code". Orig. Life. Evol. Biosph., 97, 397-403.
[61] Melcher, G. (1974). "Stereospecificity of the genetic code". J. Mol. Evol., 3, 121-141.
[62] Balasubramanian, R, Seetharamulu, P, Raghunathan, G. (1980). "A conformational rationale for the origin of the mechanism of nucleiacid-directed protein synthesis of “living” organisms". Origins Life, 10, 15-30.
[63] Shimizu, M. (1982). "Molecular bases for the genetic code". J. Mol. Evol., 18, 297- 303.
[64] Yarus, M. (1988) "A specific amino acid binding site composed of RNA". Science,
240, 1751-1758.
[65] Yarus, M. (1989). "Specificity of arginine binding by the tetrahymena intron".
Biochemistry, 28, 980-988.
[66] Yarus, M. (1991). "An RNA-amino acid complex and the origin of the genetic code".
New Biologist, 3, 183-189.
[67] Yarus, M. (1993). An RNA-amino acid affinity. En: The RNA World. Gesteland, RF, Atkins, JF (eds). New York, Cold Spring Harbor Laboratory Press, 205-217.
[68] Sonneborn, TM. (1965). Degeneracy of the genetic code, extent, nature, and genetic implications. En: Evolving genes and proteins. Bryson, V, Vogel, HJ (eds). New York, Academic Press, 377-397.
[69] Woese, CR, Dugre, DH, Dugre, SA, Kondo, M, Saxinger, WC. (1966). "On the fundamental nature and evolution of the genetic code". Cold Spring Harbor Symp. Quant. Biol., 31, 723-736.
[70] Woese, CR. (1965). "Order in the genetic code". Proc. Nat. Acad. Sci., EUA, 54, 71- 75.
[71] Webber, AL, Lacey, JC. (1978). "Genetic code correlations: amino acids and their anticodon nucleotides". J. Mol. Evol., 11, 199-210.
[72] Jungck, JR. (1978). "The genetic code as a periodic table". J. Mol. Evol., 11, 211-224.
[73] Lacey, JC, Mullins, DW. (1983). "Experimental studies related to the origin of the genetic code and the process of protein synthesis - a review". Origins Life, 13, 3-42.
[74] Blalock, JE, Smith, EM. (1984). "Hydropathic anticomplementarity of amino-acids based on the genetic code". Biochem. Biophys. Rev. Commun., 121, 203-207.
[75] Taylor, FJR, Coates, D. (1989). "The code within the codons". Biosystems, 22, 177- 187.
[76] Lacey, JC, Wickramasinghe, NS, Cook, GW. (1992). "Experimental studies on the origin of the genetic code and the process of protein synthesis a review". Origins Life Evol. Biosphere., 22, 243-275.
[77] Lacey, JC, Wickramasinghe, NS, Cook, GW, Anderson, G. (1993). "Coupling of character and of chirality in the origin of the genetic system". J. Mol. Evol., 37, 233-239.
[78] Freier, SM, Kierzek, R, Jaeger, JA, Sugimoto, N, Caruthers, MH, Neilson, T, Turner, DH. (1986). "Improved free-energy parameters for prediction of RNA duplex stability". Proc. Nat. Acad. Sci. USA, 83, 9373-9377.
[79] Turner, DH, Sugimoto, N, Jaeger, JA, Longfellow, CE, Freier, SM, Kierzek, R. (1987). "Improved parameters for prediction of RNA structure". Cold Spring Harb. Symp. Quant. Biol., 52, 123-133.
[80] Turner, DH, Bevilacqua, PC. (1993). Thermodynamic considerations for evolution by RNA. En: The RNA world. Gesteland, RF, Atkins, JF (eds). New York, Cold Spring Harbor Laboratory Press.
[81] Lehman, J. (2000). "Physico-chemical constraints connected with the coding properties of the genetic system". J. theor. Biol., 202, 129-144.
[82] Kuhn, H, Waser, J. (1994). "On the origin of the genetic code". FEBS, 352, 259-264.
[83] Milstien, S, Cohen, LA. (1970). "Rate acceleration by stereopopulation control: models for enzyme action". Proc. Nat. Acad. Sci., EUA, 67, 1143-1147.
[84] Eigen, M, Schuster, P. (1979). The hypercycle. A principle of natural self- organization. Berlin, Springer-Verlag.
[85] Miller, SL, Orgel, LE. (1974). The origins of life on Earth. New Jersey, Prentice Hall,.
[86] Jukes, TH. (1996). "On the prevalence of certain codons (“RNY") in genes for proteins". J. Mol. Evol, 42, 377–381.
[87] Shepherd, JCW. (1981). "Periodic correlations in DNA sequences and evidence suggesting their evolutionary origin in a comma-less genetic code." J. Mol. Evol., 17, 94– 102.
[88] Shepherd, JCW. (1990). "Ancient patterns in nucleic acid sequences". Methods. Enzymol., 183, 180–192.
[89] Konecny, J, Schöniger, M, Hofacker, L. (1995). "Complementary coding conforms to the primeval comma-less code". J. theor. Biol., 173, 263–270.
[90] García, JA, Alvarez, S, Flores, A, Govezensky, T, Bobadilla, JR, José, MV. (2004). "Statistical analysis of the distribution of amino acids in Borrelia burgdorferi genome under different genetic codes". Physica A, 342, 288-293.
[91] Crick, FHC. (1968). "The origin of the genetic code". J. Mol. Biol., 38, 367-379.